Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
Scomposizione della devianza
K=1,…, r Dev(Xk)= =Dev(Xk)+Nk(mk–m)2 Dev(X)=
= =Dev(Xk)+Nk(mk–m)2. Dev(X)=")
2
Intervalli di confidenza
Errore= Rischio=a =

4
m m

5
Misure di distanza variabili 1 2 . S O unità w
2 . S O unità w Unità i ( wi1, wi2 , wi3 , … , wiO) infatti, in uno spazio bidimensionale: unità i (wi1, wi2)
 infatti, in uno spazio bidimensionale: unità i (wi1, wi2)")
6
Nel caso che le O variabili sono espresse in unità di misura diverse:
dove: (wi–wj)= |( wi1–wj1) (wi2 – wj2) … (wiO–wjO)| (wi–wj)=a= |a1 a2 … aO| d2(wi,wj)= (1x1) (1xn) ( nxn) (nx1)
= |( wi1–wj1) (wi2 – wj2) … (wiO–wjO)| (wi–wj)=a= |a1 a2 … aO| d2(wi,wj)= (1x1) (1xn) ( nxn) (nx1)")
7
ricordando che: Matrice di varianze e covarianze: V=

8
Somiglianza tra variabili
Per rendere le variabili indipendenti tra loro, occorre moltiplicare le distanze tra le variabili per l’inversa della matrice di varianze e covarianze

9
La matrice inversa AA-1 = A-1A = Inxn
Sia A una matrice quadrata di ordine nxn, si dice matrice inversa di A e si indica con A-1 la matrice dello stesso ordine di A tale che: AA-1 = A-1A = Inxn Per capire se una matrice è dotata o meno di inversa, occorre calcolarne il determinante. Quando Det(A)=0 la matrice non è dotata di inversa. In caso contrario, la matrice è dotata di inversa (non singolare) Il determinante di una matrice (solo per le quadrate) è un numero che viene associato ad ogni matrice quadrata tale che: |A| di ordine 1x1 coincide col numero stesso |A| di ordine 2x2 è pari a: a11a22–a21a12
=0 la matrice non è dotata di inversa. In caso contrario, la matrice è dotata di inversa (non singolare) Il determinante di una matrice (solo per le quadrate) è un numero che viene associato ad ogni matrice quadrata tale che: |A| di ordine 1x1 coincide col numero stesso. |A| di ordine 2x2 è pari a: a11a22–a21a12.")
10
Il rango di una matrice Sia A una matrice di ordine mxn, considerando le colonne di A come vettori di ordine m, il rango di A è il massimo numero di vettori colonna linearmente indipendenti. n vettori si definiscono linearmente indipendenti se nessuno di essi è esprimibile come combinazione lineare degli altri. Esempio di vettori linearmente dipendenti: (2, -1, 1), (1, 0, 1) e (3, -1, 2) il terzo vettore è la somma dei primi due Data una matrice quadrata di ordine n: r(A)=n se e solo se |A| 0 l’inversa di una matrice esiste se e solo se la matrice ha rango massimo
, (1, 0, 1) e (3, -1, 2) il terzo vettore è la somma dei primi due. Data una matrice quadrata di ordine n: r(A)=n se e solo se |A| 0. l’inversa di una matrice esiste se e solo se la matrice ha rango massimo.")
11
L’Analisi in Componenti Principali
In generale, in un’indagine statistica sono rilevate, per ciascuna unità, un numero elevato di variabili. Spesso l’obiettivo dell’analisi consiste nel pervenire alla conoscenza di fenomeni non direttamente rilevabili (es. qualità della vita), ma alla cui determinazione concorrono numerose variabili atte ad evidenziarne i molteplici aspetti (inquinamento dell’aria, fruibilità dei servizi pubblici, facilità di parcheggio, tasso di criminalità, ecc.). necessità di sintetizzare tutte le variabili rilevati in uno o in pochi indicatori
, ma alla cui determinazione concorrono numerose variabili atte ad evidenziarne i molteplici aspetti (inquinamento dell’aria, fruibilità dei servizi pubblici, facilità di parcheggio, tasso di criminalità, ecc.). necessità di sintetizzare tutte le variabili rilevati in uno o in pochi indicatori.")
12
L’Analisi in Componenti Principali
Nel caso in cui su un collettivo statistico vengono rilevate, per ogni unità, solo due variabili, è possibile proiettare su un sistema cartesiano i punti unità: due punti tra loro vicini significa che quegli individui hanno caratteristiche simili Qualora si proiettino i punti variabili due punti tra loro vicini significa che tra le variabili sussiste una relazione

13
L’Analisi in Componenti Principali
Problema Avendo rilevato n variabili su un collettivo di p unità, si vuole passare da uno spazio a n dimensioni ad uno spazio a m dimensioni (m<n) con la minima perdita di informazioni (variabilità)
 con la minima perdita di informazioni (variabilità)")
14
L’Analisi in Componenti Principali
Esempio di passaggio da un sistema bidimensionale ad uno unidimensionale massimizzare (of)2
2.")
15
L’Analisi in Componenti Principali
Il passaggio da un sistema di riferimento ad un altro avviene semplicemente operando una combinazione lineare delle coordinate che i punti presentano nello spazio precedente. Infatti nel caso di passaggio ad un nuovo sistema i cui assi sono paralleli ai precedenti, è sufficiente sottrarre alle coordinate di partenza quelle del punto assunto come origine degli assi nel caso di passaggio da un nuovo sistema i cui assi non sono ortogonali tra loro ad un nuovo sistema di assi ortogonali, occorre moltiplicare le coordinate di partenza per il coseno dell’angolo del nuovo sistema

16
L’Analisi in Componenti Principali
Da un punto di vista matematico: La proiezione dei punti da un sistema X Rn ad un nuovo sistema di riferimento Y Rm, con m<n, richiede l’applicazione di una funzione: A: X AX = Y dove la matrice A costituisce l’operatore di trasformazione di una grandezza da uno spazio Rn ad un nuovo spazio Rm. Per massimizzare la somma delle proiezioni dei punti sui nuovi assi, occorre prendere una retta non passante per l’origine dei vecchi assi. necessità di cambiare origine degli assi, che viene individuata nel baricentro della nube dei punti (punto nell’iperspazio le cui coordinate sono pari al valore medio di ogni variabile). equivale a trasformare ciascuna variabile considerando, in luogo dei valori xi, gli scarti dalla propria media.
. equivale a trasformare ciascuna variabile considerando, in luogo dei valori xi, gli scarti dalla propria media.")
17
L’Analisi in Componenti Principali
Da un punto di vista matematico: Si inizia individuando un primo asse (retta) in modo che le proiezioni dei punti sulla stessa sia massima. Per individuare la seconda dimensione, si sceglie una ortogonale alla prima già individuata e che massimizza sempre la proiezione dei punti. Si(ofi)2=(Xu)’(Xu)=u’X’Xu= max con u vettore delle nuove coordinate incognito X matrice dei dati di partenza nello spazio Rn Indicando A=X’X: Si(ofi)2=u’Au= max con il vincolo u’Mu=1 di ortonormalità (uiuj=0) e normalizzati} con M matrice simmetrica positiva
 in modo che le proiezioni dei punti sulla stessa sia massima. Per individuare la seconda dimensione, si sceglie una ortogonale alla prima già individuata e che massimizza sempre la proiezione dei punti. Si(ofi)2=(Xu)’(Xu)=u’X’Xu= max. con. u vettore delle nuove coordinate incognito. X matrice dei dati di partenza nello spazio Rn. Indicando A=X’X: Si(ofi)2=u’Au= max. con il vincolo u’Mu=1 di ortonormalità (uiuj=0) e normalizzati} con M matrice simmetrica positiva.")
18
L’Analisi in Componenti Principali
Da un punto di vista matematico: Trattandosi di un problema di massimizzazione, si ricorre quindi ai moltiplicatori di Lagrange: L=u’Au – l(u’Mu–1)=max e derivando rispetto ad u: 2Au–2 lMu=0 Au= lMu e moltiplicando ambo i membri per u’: u’Au= lu'Mu e siccome u’Mu=1 u’Au= l l è il parametro che massimizza la somma delle proiezioni dei punti dello spazio sull’asse u Essendo M una matrice invertibile: M-1Au=lu u autovettore della matrice M-1A corrispondente all’autovalore l.
=max. e derivando rispetto ad u: 2Au–2 lMu=0. Au= lMu. e moltiplicando ambo i membri per u’: u’Au= lu Mu. e siccome u’Mu=1. u’Au= l. l è il parametro che massimizza la somma delle proiezioni dei punti dello spazio sull’asse u. Essendo M una matrice invertibile: M-1Au=lu. u autovettore della matrice M-1A corrispondente all’autovalore l.")
19
Brevi richiami di algebra lineare
Un autovettore di una trasformazione lineare è un vettore non nullo che non cambia direzione nella trasformazione Il vettore può cambiare quindi solo per moltiplicazione di uno scalare, chiamato autovalore. Il piano cartesiano e lo spazio euclideo sono esempi particolari di spazi vettoriali: ogni punto dello spazio può essere descritto tramite un vettore che collega l'origine al punto. Rotazioni sono esempi particolari di trasformazioni lineari dello spazio: ciascuna di queste trasformazioni viene descritta agevolmente dall'effetto che produce sui vettori. In particolare, un autovettore è un vettore che nella trasformazione viene moltiplicato per un fattore scalare λ. Nel piano o nello spazio cartesiano, questo equivale a dire che il vettore non cambia direzione.

20
Brevi richiami di algebra lineare
Riprendendo l’espressione M-1Au=lu e portando tutto al I membro: M-1Au–lu=0 (M-1A–Il)u=0 (M-1A–Il)=0 la cui soluzione si ottiene ponendo uguale a zero il determinante della matrice al I membro: det(M-1A–Il)u=0 equazione caratteristica in quanto le radici del seguente polinomio caratteristico p(x), con variabile x, associato ad una matrice quadrata A: p(x) = det(A − xI) sono proprio gli autovalori di A. ad ogni autovalore si possono associare infiniti autovettori per A matrice reale e simmetrica, gli autovettori corrispondenti ad autovalori diversi sono linearmente indipendenti e quindi ortogonali tra loro
u=0. (M-1A–Il)=0. la cui soluzione si ottiene ponendo uguale a zero il determinante della matrice al I membro: det(M-1A–Il)u=0 equazione caratteristica. in quanto le radici del seguente polinomio caratteristico p(x), con variabile x, associato ad una matrice quadrata A: p(x) = det(A − xI) sono proprio gli autovalori di A. ad ogni autovalore si possono associare infiniti autovettori. per A matrice reale e simmetrica, gli autovettori corrispondenti ad autovalori diversi sono linearmente indipendenti e quindi ortogonali tra loro.")
21
Esempio Passi dell’AF: calcolo della matrice di correlazione o di covarianza stima dei fattori, che vengono estratti ad es. con l’ACP rotazione dei fattori per facilitarne l’interpretazione calcolo, per ogni osservazione, dei punteggi in relazione a ciascun fattore L’ACP si serve di combinazioni lineari delle variabili di partenza che consentono di catturare la maggiore variabilità delle stesse. La prima combinazione lineare cattura l’importo di variabilità più elevato nel campione; la II la più elevata variabilità rimanente, in una dimensione indipendente rispetto alla precedente.

22
Esempio La variabilità associata a ciascuna componente è rappresentata dal corrispondente autovalore. Il valore di ciascun autovalore esprime la parte della variabilità della nuvola dei punti nello spazio multivariato di partenza catturata dalla nuova dimensione espressa dall’autovettore associato a quell’autovalore. La comunalità, per ogni variabile, è la quota della varianza di quella variabile che può essere spiegata dai fattori comuni; essa è espressa dalla correlazione multipla quadra della variabile con i fattori. Le comunalità delle variabili di partenza prima dell’applicazione dell’ACP sono dunque pari a 1. Successivamente, si esaminano le comunalità rispetto ali primi fattori estratti e considerati ai fini dell’analisi. La tabella delle comunalità mostra dunque la % di variabilità che per ogni variabile è spiegata da tali primi due fattori

23
Esempio Scree plot: è il grafico che in ascissa ha le componenti fattoriali e in ordinata il valore dell’autovalore associato. È utile per decidere quante componenti considerare. Matrice delle componenti: mostra i coefficienti (loadings) che legano le variabili alle componenti non ruotate. Sono cioè i coefficienti di correlazione calcolati tra ciascuna variabile e ciascun fattore. Pertanto consentono di evidenziare ogni variabile a quale componente è maggiormente collegata. Matrice delle componenti ruotate: dopo la rotazione, che è un’operazione che spesso risulta utile effettuare per favorire l’interpretazione dei fattori, i coefficienti cambiano. Infatti, scopo della rotazione è proprio quello di rendere i coefficienti maggiori ancora più grandi e quelli minori ancora più piccoli
 che legano le variabili alle componenti non ruotate. Sono cioè i coefficienti di correlazione calcolati tra ciascuna variabile e ciascun fattore. Pertanto consentono di evidenziare ogni variabile a quale componente è maggiormente collegata. Matrice delle componenti ruotate: dopo la rotazione, che è un’operazione che spesso risulta utile effettuare per favorire l’interpretazione dei fattori, i coefficienti cambiano. Infatti, scopo della rotazione è proprio quello di rendere i coefficienti maggiori ancora più grandi e quelli minori ancora più piccoli.")
24
Esempio Test KMO e test di sfericità di Bartlett: riproduce i valori assunti dalla misura di Kaiser-Meyer-Olkin La misura di Kaiser-Meyer-Olkin è un indice normalizzato che mette a confronto l’entità complessiva dei coefficienti di correlazione semplice rij tra ogni coppia Xi e Xj di variabili e quella dei corrispondenti coefficienti di correlazione parziali rij,rest, rese costanti tutte le altre variabili: quanto più questo indice vale 1, tanto più il modello fattoriale è adeguato ai dati. Test di sfericità di Bartlett: è basato sull’assunto di normalità distributiva delle variabili osservate, consente di saggiare l’ipotesi che la matrice di correlazione coincida con la matrice identità; al crescere del valore del testi di Bartlett, decresce il corrispondente p-value.

25
Esempio Consideriamo alcuni indicatori della dotazione di strutture turistico-ricettive inerenti le province italiane.

26
Esempio n. esercizi alberghieri, n. letti negli esercizi alberghieri, n. di camere negli esercizi alberghieri e n. di bagni negli esercizi alberghieri: tutte indicatrici del grado di presenza delle strutture alberghiere, ponendone in evidenza anche le caratteristiche dimensionali. n. di bagni può denotare, là dove essa si discosti maggiormente dal numero di stanze, la maggiore presenza di strutture di basso livello. presenza di campeggi e villaggi turistici tipologia particolare di turismo. Ci si attende che presentino i valori più elevati in corrispondenza delle maggiori località turistiche, soprattutto quelle balneari, a discapito, principalmente, del turismo nelle città d’arte, nelle quali la forma di alloggio più comune, si sa, è rappresentata dagli alberghi e dai bed and breakfast che sono compresi nelle ultime due variabili, ovvero n. di altri esercizi e n. di letti negli altri esercizi, così come gli agriturismo, che risultano sempre più numerosi.

27
Esempio n. di alloggi privati in affitto e n. di letti negli alloggi privati ci si attende che presentino i valori più elevati in quelle province in cui il turismo è maggiormente presente, nelle quali, quindi, sono offerti con maggiore frequenza anche semplici appartamenti in fitto. L’esame visivo dei dati in parte conferma queste prime deduzioni. presenza di alcuni valori mancanti per le variabili n. di campeggi e villaggi turistici e n. di letti nei campeggi e villaggi turistici e in pochi casi anche in quelle che si riferiscono alle tipologie di strutture ricettive definite “altre” (tutte quelle che non si riferiscono agli alberghi). tali dati mancanti possono derivare dall’assenza del fenomeno, come quello delle province di Benevento e Avellino in relazione alla presenza di campeggi e di villaggi turistici, ma in altri casi evidenziano senz’altro la mancata rilevazione del fenomeno, come nel caso del numero di alloggi privati in affitto in province come Roma.
. tali dati mancanti possono derivare dall’assenza del fenomeno, come quello delle province di Benevento e Avellino in relazione alla presenza di campeggi e di villaggi turistici, ma in altri casi evidenziano senz’altro la mancata rilevazione del fenomeno, come nel caso del numero di alloggi privati in affitto in province come Roma.")
28
Esempio In particolare, mentre in 91 casi su 95 è rilevato il numero di campeggi e villaggi ed il numero dei letti negli stessi, in soli 85 casi su 95 ne è rilevata invece la superficie, per cui si ritiene opportuno eliminare dall’analisi questa variabile in quanto l’informazione che essa fornisce dà uno scarso contributo al quadro informativo già fornito con le variabili sul numero di campeggi e villaggi e sul numero di letti negli stessi. Risultano però mancanti anche i dati sul numero di alloggi privati e sul numero di letti negli stessi in ben 14 casi. Analisi listwise si finisce per perdere ben 33 osservazioni su 95, ovvero il 35% dei dati disponibili. Analisi pairwise sebbene consenta di recuperare parte dell’informazione persa, rende più complessa l’interpretazione del fenomeno.

29
Esempio

30
Esempio Le statistiche descrittive evidenziano l’estrema variabilità di tutte le variabili esaminate. In tutti i casi, infatti, la deviazione standard risulta superiore al valore della corrispondente media aritmetica. Esse, inoltre, presentano tutte una distribuzione marcatamente asimmetrica a destra e valori, talvolta, anche molto elevati dell’indice di curtosi, ad indicare la significativa deviazione dall’ipotesi di normalità delle variabili esaminate, che in tutti i casi hanno distribuzione ipernormale.

31
Esempio

32
Esempio Dall’analisi della matrice di correlazione notiamo come tutte le variabili siano legate da una correlazione di tipo diretto. Non ci si attende, quindi, dalla proiezione delle variabili sul piano fattoriale grandi contrapposizioni. Gli indicatori relativi agli alberghi sono tutti, come c’era da attendersi, fortemente correlati tra loro. Gli indicatori dei villaggi turistici presentano una correlazione elevata solo tra loro mentre con gli altri indicati essa si attesta in tutti i casi sotto lo 0,4. Stessa cosa vale anche per gli “altri” esercizi. Si esegue l’analisi decidendo di considerare tutti i fattori i cui autovalori sono maggiori di 1.

33
Esempio Kaiser-Meyer-Olkin: indice normalizzato, quanto più si avvicina a 1, tanto più il modello fattoriale è adeguato ai dati. Test di sfericità di Bartlett: basato sull’assunto di normalità distributiva delle variabili osservate. Verifica l’ipotesi secondo cui matrice di correlazione dei dati coincide con la matrice identità (al crescere del valore del test, decresce il corrispondente p-value associato).
.")
34
Esempio Il test di Kaiser Meyer Olkin evidenzia, con un valore di 0,738, l’adeguatezza del dataset al trattamento con la tecnica dell’ACP. Tale test esprime infatti la correlazione media esistente tra tutte le variabili inserite nell’analisi, considerate a coppie ed i corrispondenti coefficienti di correlazione parziali della medesima coppia di variabili rispetto a tutte le altre. Il test di Bartlett, invece, che assume la normalità delle variabili, consente ampiamente di rigettare l’ipotesi nulla in base alla quale la matrice di correlazione non è significativamente diversa dalla matrice identità.

35
Esempio Tavola delle comunalità (quota della varianza di ciascuna variabile spiegata dai fattori prescelti)
")
36
Esempio La tavola delle comunalità riporta, nella II colonna, il valore della % di variabilità spiegata dai fattori presecelti in riferimento a ciascuna variabile. Per tutte, tranne quella che si riferisce al n. di letti nel complesso degli alloggi privati in affitto, la maggior parte della variabilità è spiegata dai fattori prescelti.

37
Esempio

38
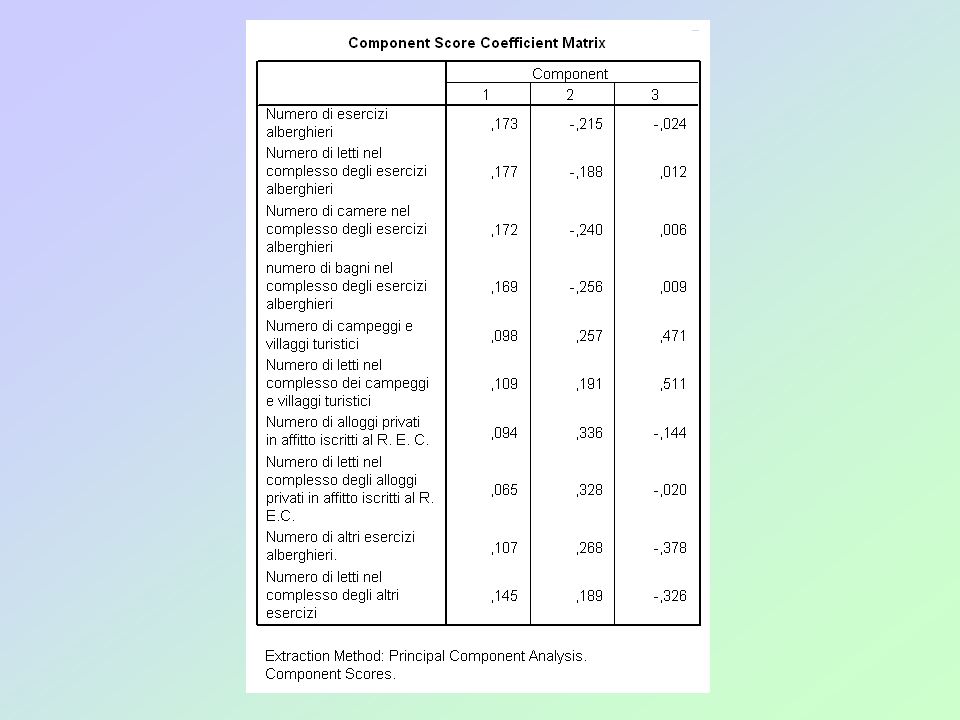
Esempio La matrice delle componenti mostra le correlazioni esistenti tra ciascuna componente e ciascuna variabile. Rispetto alla prima dimensione, tutte le variabili presentano correlazione diretta. Rispetto alla II dimensione, invece, gli indicatori riferiti alla dotazione alberghiera risultano in contrapposizione con tutti gli altri. La III componente vede invece contrapporsi gli indicatori riferiti ai villaggi ed ai campeggi a quelli inerenti le “altre” strutture”.

39
Esempio Riteniamo sufficiente considerare le prime 3 componenti che, assieme, consentono di spiegare quasi l’83% della variabilità del set di variabili di partenza. Il software ha selezionato nell’analisi proprio queste prime 3 componenti in quanto è stata scelta l’opzione di considerare tutte le componenti i cui autovalori avessero un valore >1

40
Esempio

41
Proiezione delle variabili sul sistema cartesiano tridimensionale definito dalle prime tre componenti

43
Proiezione dei punti-variabili sulle prime due dim.

44
Proiezione dei punti-osservaz. sulle II due dim.

45
Esempio I componente: espressione del diverso grado di vocazione turistica delle province considerate. Contrapposizione, soprattutto, tra le province di Venezia, Trento e Forlì da una parte, ed Arezzo, Asti e Alessandria, dall’altra. II componente: sembra invece contrapporre le variabili indicatrici della dotazione alberghiera a quelle che fanno riferimento agli altri tipi di strutture. Dal grafico in cui sono proiettate le province, notiamo infatti la contrapposizione tra le città di Forlì, Bolzano e Roma, che presentano una dotazione alberghiera notevolissima, e città come Trento o Verona in cui, pur essendo a forte vocazione turistica, con dotazione alberghiera di tutto rispetto, è molto più elevata l’incidenza di altre strutture, come quelle di villaggi e campeggi.

46
Gli stimatori Uno stimatore è una variabile casuale utilizzata per stimare una determinata caratteristica q della popolazione: T=t(X1, X2, …,Xn). Data una popolazione di N unità, volendo pervenire ad una stima t del valore del parametro q della popolazione, si procede attraverso un campione di dimensione n estratto casualmente dalla popolazione. A partire da una popolazione di dimensione N, i campioni di n elementi estraibili casualmente sono tanti e in corrispondenza di ciascuno di essi, si avrà un dato valore della stima t. Lo stimatore è quindi una variabile casuale con una propria distribuzione che assume i diversi valori della stima rilevati nei vari campioni.

47
Proprietà degli stimatori
Correttezza Lo stimatore T è uno stimatore corretto di q se E(t)=q. Definendo la distorsione come la differenza tra E(t) e q, diremo quindi che uno stimatore corretto ha distorsione nulla.
=q. Definendo la distorsione come la differenza tra E(t) e q, diremo quindi che uno stimatore corretto ha distorsione nulla.")
48
Proprietà degli stimatori
Efficienza Dati due stimatori corretti, T1 e T2, si dirà che T1 è più efficiente di T2 se e solo se Var(T1)<Var(T2). Consistenza Uno stimatore si definisce consistente se la sua precisione aumenta all’aumentare della dimensione campionaria
<Var(T2). Consistenza. Uno stimatore si definisce consistente se la sua precisione aumenta all’aumentare della dimensione campionaria.")
49
La regressione lineare multipla
nel caso di due sole variabili: Y=a+b1X1+b2X2+e stimato con: Y*=a+b1X1+b2X2

50
La regressione lineare multipla
y*=a+b1X1+b2X2+e E, secondo il criterio dei minimi quadrati:

51
La regressione lineare multipla
y*=a+b1X1+b2X2+e

52
La regressione lineare multipla
E, attraverso passaggi successivi:

53
La regressione lineare multipla
piano di regressione passante per il punto identificato dalle medie di Y, X1 e X2

54
La regressione lineare multipla
Fissando: retta di regressione parziale di Y rispetto a X1 quando il carattere X2 è considerato fisso e pari ad un certo valore esprime come varia in media Y al variare di X1 quando X2 è considerata costante facendo cambiare valore a X2 si hanno tante rette parallele e b1 si denomina coefficiente di regressione parziale di Y rispetto a X1 in tenendo costante X2

55
Coefficiente di correlazione parziale
Coefficiente di correlazione parziale tra X1 e X2, fissato X3: dove: b12,3: coefficiente di regressione parziale di X1 rispetto a X2, fissato X3 b21,3: coefficiente di regressione parziale di X2 rispetto a X1, fissato X3

56
Ipotesi base modello di regressione lineare multipla
variabili continue e misurate senza errore variabile dipendente Y ~ N per le variabili indipendenti l’ipotesi di normalità è meno restrittiva, in quanto incide solo sull’efficienza degli stimatori 3. ei ~ N(0, s2) i 3.1. l’ipotesi di normalità dell’errore è necessaria solo per eseguire i test di significatività per piccoli campioni 3.2. l’errore non deve essere sistematico, ma casuale: E(ej)= per ogni j (incide solo su a) 3.3. Var(et)=s2=cost (assenza di eteroschedasticità) per la verifica, si può dividere in fasce il piano e confrontare i residui in ciascuna fascia di piano (in orizzontale)
 i l’ipotesi di normalità dell’errore è necessaria solo per eseguire i test di significatività per piccoli campioni l’errore non deve essere sistematico, ma casuale: E(ej)=0 per ogni j (incide solo su a) 3.3. Var(et)=s2=cost (assenza di eteroschedasticità) per la verifica, si può dividere in fasce il piano e confrontare i residui in ciascuna fascia di piano (in orizzontale)")
57
Ipotesi alla base del modello di regressione lineare multipla
4) Cov(ej,ei)=0 i, j (tranne che per i=j) considero la variabile residuo così come è e la stessa ritardata di un periodo (ei, ei-1); (ei-1, ei-2) …; in caso di assenza di correlazione casualità ordinamento dei residui rispetto asse delle ascisse (nelle serie storiche è il tempo) 5) Cov(xj,e)=0 indipendenza dell’errore da tutte le variabili indipendenti 6) Assenza di perfetta collinearità (multicollinearità) le variabili indipendenti presentano sempre un certo grado di correlazione tra loro, ma non deve essere eccessiva
 Cov(ej,ei)=0 i, j (tranne che per i=j) considero la variabile residuo così come è e la stessa ritardata di un periodo (ei, ei-1); (ei-1, ei-2) …; in caso di assenza di correlazione casualità. ordinamento dei residui rispetto asse delle ascisse (nelle serie storiche è il tempo) 5) Cov(xj,e)=0. indipendenza dell’errore da tutte le variabili indipendenti. 6) Assenza di perfetta collinearità (multicollinearità) le variabili indipendenti presentano sempre un certo grado di correlazione tra loro, ma non deve essere eccessiva.")
58
Valutazione dell’importanza di ciascun regressore
Approccio basato sulla matrice di correlazione: fornisce l’importanza relativa delle variabili: più è alto il valore assoluto del coefficiente di correlazione, più alta è l’associazione lineare. Il test t calcolato sui coefficienti B di correlazione parziale (coefficiente aggiustato per le altre variabili indipendenti) esprime la probabilità che ogni singola variabile intervenga nella spiegazione lineare della variabile dipendente
 esprime la probabilità che ogni singola variabile intervenga nella spiegazione lineare della variabile dipendente.")
59
Valutazione dell’importanza di ciascun regressore
Coefficiente di correlazione parziale: esprime la correlazione fra la variabile indipendente X e la variabile dipendente quando gli effetti lineari delle altre variabili indipendenti sono stati rimossi Approccio basato sull’Rchange: incremento di R2 ottenuto introducendo la nuova variabile

60
Test di validazione del modello
Test d’ipotesi: 1) per ogni singolo coefficiente H0: bi=0 H1: bi 0 La variabile di riferimento è (bi–bi)/sbi La distribuzione di riferimento è la t di Student con n–k gdl poiché si tratta di un caso di differenze tra medie e la varianza è stimata sulla base dei dati campionari p-value, area associata alla coda delimitata dal valore empirico Il test va fatto anche sull’intercetta 2) Su tutto il modello H0: b1=b2=…=bk=0 (coefficienti di regressione tutti nulli) H1: b1, b2, …, bk 0 (almeno un coefficiente 0) Variabile di riferimento: da confrontare con
 per ogni singolo coefficiente. H0: bi=0. H1: bi 0. La variabile di riferimento è (bi–bi)/sbi. La distribuzione di riferimento è la t di Student con n–k gdl poiché si tratta di un caso di differenze tra medie e la varianza è stimata sulla base dei dati campionari. p-value, area associata alla coda delimitata dal valore empirico. Il test va fatto anche sull’intercetta. 2) Su tutto il modello. H0: b1=b2=…=bk=0 (coefficienti di regressione tutti nulli) H1: b1, b2, …, bk 0 (almeno un coefficiente 0) Variabile di riferimento: da confrontare con.")
61
Test di validazione del modello
R2 in un modello di regressione multipla esprime l’effetto combinato dell’intera equazione sulla previsione (quadrato della correlazione tra valori veri e valori previsti)
")
62
Errori di specificazione
sono state incluse variabili non rilevanti g=a+b1X1+e modello vero g=a+b1X1+b2X2+e modello stimato se X2 non è utile, mi aspetterei che la stima del suo coefficiente angolare sia nulla: [E(b2)=0] b1 stimatore corretto di b1, ma perde in efficienza L’effetto dell’inclusione di X2 sulla formula di sb1 si ripercuote sulla quantità a denominatore, che non è più n–2 bensì n–3; per cui sb1 risulta una quantità minore e sb1 risulta maggiorato!
=0] b1 stimatore corretto di b1, ma perde in efficienza. L’effetto dell’inclusione di X2 sulla formula di sb1 si ripercuote sulla quantità a denominatore, che non è più n–2 bensì n–3; per cui sb1 risulta una quantità minore e sb1 risulta maggiorato!")
63
Errori di specificazione
sono state omesse variabili rilevanti g=a+b1X1+b2X2+e modello vero g=a+b1X1+e modello stimato Var(Y)=var(X1)+Var(X2)+var(e) Avendo stimato il II modello, a parità di varianza di Y, non avendo considerato X2, la sua varianza va a confluire, anziché nel modello, nell’errore che, pertanto, non si distribuirà nemmeno più normalmente! correlazione tra e e X1 (residui eteroschedastici, con un pattern al loro interno) stimatore di b1 distorto
=var(X1)+Var(X2)+var(e) Avendo stimato il II modello, a parità di varianza di Y, non avendo considerato X2, la sua varianza va a confluire, anziché nel modello, nell’errore che, pertanto, non si distribuirà nemmeno più normalmente! correlazione tra e e X1 (residui eteroschedastici, con un pattern al loro interno) stimatore di b1 distorto.")
64
Errori di specificazione
presenza di multicollinearità in caso di perfetta multicollinearità: modello stimato: g=a+b1X1+b2X2+e (equazione associata ad un piano) ma X1=p+rX2 i dati empirici, se li proietto sul piano X1X2 si dispongono tutti su una retta stiamo rappresentando in uno spazio tridimensionale un fenomeno che, in realtà, è bidimensionale Y non dipende più da X1 e X2, ma dalla variabile che si trova in corrispondenza di questo piano su cui sono disposti i punti in caso di multicollinearità quasi perfetta nel campione, ma non nella popolazione, gli stimatori OLS continuano ad essere BLUE (Best Linear Unbiased Estimators)
 ma X1=p+rX2. i dati empirici, se li proietto sul piano X1X2 si dispongono tutti su una retta. stiamo rappresentando in uno spazio tridimensionale un fenomeno che, in realtà, è bidimensionale. Y non dipende più da X1 e X2, ma dalla variabile che si trova in corrispondenza di questo piano su cui sono disposti i punti. in caso di multicollinearità quasi perfetta nel campione, ma non nella popolazione, gli stimatori OLS continuano ad essere BLUE (Best Linear Unbiased Estimators)")
65
Errori di specificazione
problemi inerenti la scelta dei regressori Occorrerebbe scegliere le variabili con forte correlazione con la variabile dipendente ma, allo stesso tempo, poco correlate con gli altri regressori Quando il data-set presenta troppe variabili, per operare una scelta, si può procedere suddividendo preventivamente in gruppi omogenei le variabili e quindi prelevando da ciascun gruppo una sola variabile ricorso a strumenti quali la cluster e l’ACP

66
Errori di specificazione
effetti della multicollinearità riduce la capacità previsiva di ogni singola variabile indipendente in modo proporzionale alla forza della sua associazione con le altre variabili indipendenti. al crescere della collinearità, decresce la varianza spiegata da ogni singola variabile indipendente mentre aumenta la frazione di variabilità spiegata collettivamente da tutte le variabili. Poiché, però, la capacità previsiva di ciascuna variabile può essere conteggiata una sola volta, quando si inseriscono nel modello variabili indipendenti con forte collinearità, la capacità di previsione totale del modello aumenta molto più lentamente. rende più difficile il processo di separazione degli effetti individuali, fa diminuire il valore di R2 e ne rende il suo aumento sempre più difficoltoso, anche se si aggiungono nuove variabili; le variabili per cui si presenta il problema possono presentare coefficienti di regressione non correttamente stimati o addirittura stimati con segno opposto.

67
Errori di specificazione
presenza di multicollinearità Conseguenze: aumento di sb e quindi degli intervalli di confidenza per i coefficiente statistica t per i test di significatività più piccola, col rischio di accettare H0 pure se essa è falsa Segnali da considerare: quasi tutti i coefficienti non sono significativamente diversi da 0, sebbene il modello sia complessivamente buono, in termini di R2 corretto cambiando di poco (eliminando 2 osservazioni o modificandole) le osservazioni campionarie o il modello, si hanno forti cambiamenti nei valori dei coefficienti eseguendo la regressione di una variabile indipendente sulle altre, si ottengono valori di R2~1 presenza di correlazioni binarie > |0,8|
 le osservazioni campionarie o il modello, si hanno forti cambiamenti nei valori dei coefficienti. eseguendo la regressione di una variabile indipendente sulle altre, si ottengono valori di R2~1. presenza di correlazioni binarie > |0,8|")
68
Errori di specificazione
presenza di multicollinearità Test per rilevarla: esame della matrice di correlazione, tolleranza o il suo inverso, che è il VIF, Variance Inflation Factor (fattore di accrescimento della varianza). La tolleranza esprime l’ammontare di variabilità della variabile indipendente prescelta che rimane non spiegata dalle altre variabili indipendenti: valori piccoli della tolleranza (elevati del VIF) esprimono alta collinearità. In SPSS il valore di tolleranza di default per escludere dalla regressione le variabili indipendenti è 0,0001, che indica che, finché la % di varianza spiegata dalle altre variabili indipendenti non supera il 99,99%, la variabile in questione non può essere esclusa dall’equazione
. La tolleranza esprime l’ammontare di variabilità della variabile indipendente prescelta che rimane non spiegata dalle altre variabili indipendenti: valori piccoli della tolleranza (elevati del VIF) esprimono alta collinearità. In SPSS il valore di tolleranza di default per escludere dalla regressione le variabili indipendenti è 0,0001, che indica che, finché la % di varianza spiegata dalle altre variabili indipendenti non supera il 99,99%, la variabile in questione non può essere esclusa dall’equazione.")
69
Errori di specificazione
autocorrelazione dei residui Cov(ej,ei) # 0 Per verificare l’autocorrelazione dei residui, occorre ordinare secondo un criterio i residui (nelle serie storiche: il tempo) Dal menu di SPSS: Graficiserie storichevariabile residui I grafici calcolano l’autocorrelazione ai vari lag; se tutte le autocorrelazioni (ai vari lag) si mantengono entro le due bande orizzontali simmetriche intorno all’origine, allora non c’è autocorrelazione dei residui correlogramma Test di Durbin-Watsan (valore ~2) per il I ordine
 # 0. Per verificare l’autocorrelazione dei residui, occorre ordinare secondo un criterio i residui (nelle serie storiche: il tempo) Dal menu di SPSS: Graficiserie storichevariabile residui. I grafici calcolano l’autocorrelazione ai vari lag; se tutte le autocorrelazioni (ai vari lag) si mantengono entro le due bande orizzontali simmetriche intorno all’origine, allora non c’è autocorrelazione dei residui. correlogramma. Test di Durbin-Watsan (valore ~2) per il I ordine.")
70
Analisi dei residui In genere, si preferisce analizzare i residui standardizzati, in modo che essi siano direttamente confrontabili. I più usati sono quelli studentizzati, i cui valori sono analoghi ai valori della t di Student. 1. diagramma con in ordinata i residui e in ascissa i valori previsti Y*i della variabile dipendente Per verificare la relazione tra ogni variabile indipendente con la variabile dipendente: grafico con in ordinata i residui e in ascissa quella variabile indipendente Per verificare la normalità distributiva dei residui: istogramma dei residui. In caso di piccoli campioni, è preferibile affidarsi al grafico di probabilità normale: se i residui sono normali, si distribuiranno su o intorno alla bisettrice del plot

71
Analisi dei residui In genere, si preferisce salvare i residui come nuova variabile e poi calcolarne le statistiche descrittive, per accertarsi che la media sia nulla e la distribuzione normale

72
Weight Least Squares Il metodo dei minimi quadrati ponderato, consigliabile in caso di presenza di eteroschedasticità, parte dal presupposto di conoscere le n varianze dei residui, che vengono direttamente inserite nel modello, dividendo le variabili del modello per st (t=1,2, …, N). stime corrette e efficienti ma: essendo ignote le varianze, il modello è inapplicabile, salvo nel caso che siano disponibili dati cross section (più rilevazioni per ogni tempo t di osservazione).
. stime corrette e efficienti. ma: essendo ignote le varianze, il modello è inapplicabile, salvo nel caso che siano disponibili dati cross section (più rilevazioni per ogni tempo t di osservazione).")
Presentazioni simili
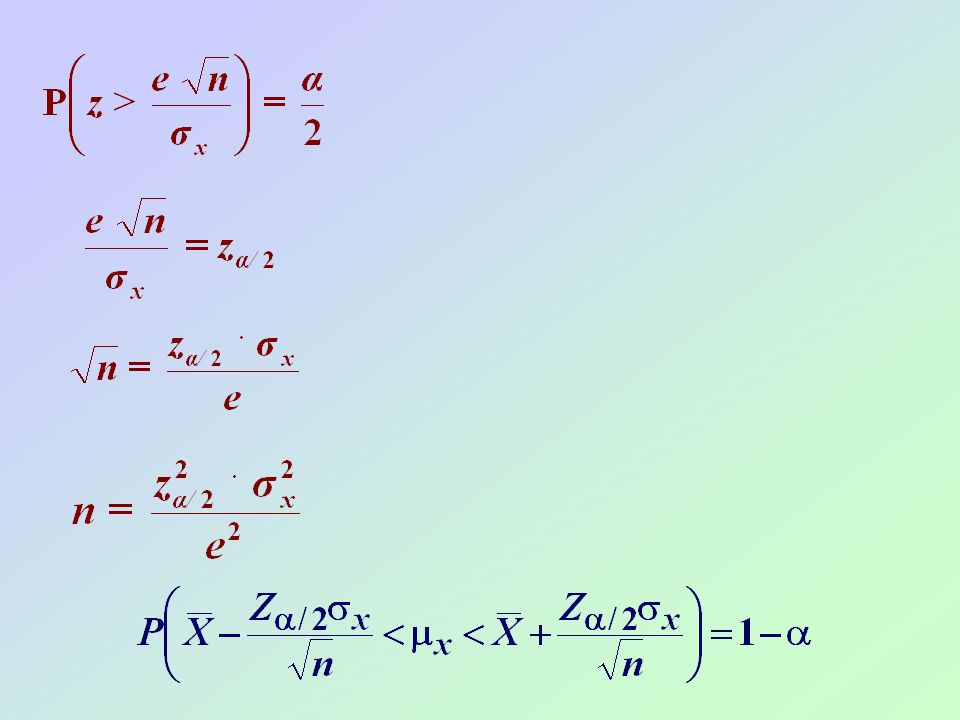


















>")
