Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
Gruppo del supporto regionale
Item Analysis: Valutazione di affidabilità dei test: Rilevazione Nazionale del SIF Z. Adam Gruppo del supporto regionale Per la valutazione 15 Dicembre 2005 Facilitation skills offer immediate, practical benefits to any group process. As facilitator, your role is to set the agenda, encourage participation, and guide the pace of the meeting. Use these Dale Carnegie Training® strategies to help make your meeting a success. You can provide handouts to focus the discussion and give attendees a place to record their ideas. If you print handouts with three slides per page, PowerPoint will automatically include blank lines for your meeting participants to take notes.

2
Legenda e istruzioni per la lettura dei dati INValSI - Sicotem © 1996/ Work in progress - Updated version, Media: Media aritmetica, valore centrale di una distribuzione somma di tutti i valori di una distribuzione divisa per il numero dei casi. Ad esempio l'altezza media degli alunni di una classe è data dalla somma delle altezze di ciascun alunno diviso il numero totale degli alunni. Mediana: Valore centrale di una distribuzione sopra il quale e sotto il quale ricade la metà dei casi. Ad esempio la mediana dell'altezza degli alunni di una classe è quel valore dell'altezza al di sopra e al di sotto del quale si troverà il 50% dei valori delle altezza degli alunni. Moda: Valore che ricorre più frequentemente in una variabile. Se esistono valori pari merito viene considerato come Moda il valore più basso. Nell'esempio considerato la moda è l'altezza che ricorre più frequentemente tra gli alunni della classe. Minimo: Valore più basso ottenuto per una variabile. Nell'esempio considerato il minimo corrisponde all'altezza minore riscontrata tra gli alunni della classe. Massimo: Valore più alto ottenuto per una variabile. Nell'esempio considerato il massimo corrisponde all'altezza maggiore riscontrata tra gli alunni della classe. Deviazione Standard: È la misura della dispersione dei valori intorno alla Media. Un basso valore della deviazione standard indica che i valori assunti dalla variabile sono concentrati intorno alla media ed esprime omogeneità di dati. Al contrario, un alto valore della deviazione standard indica che i valori assunti dalla variabile si discostano molto dalla media ed esprime disomogeneità di dati. Nell'esempio considerato se l'altezza media di una classe è di 170cm si ha un'alto valore della deviazione standard se l'altezza dei singoli alunni si discosta molto dal valore dell'altezza media, quindi troveremo alunni alti 195cm, oppure 150cm. Al contrario si ha un basso valore della deviazione standard se le altezze dei singoli alunni si avvicinano al valore dell'altezza media, quindi avremo alunni alti 175cm oppure 165cm.

3
Leggenda per la lettura dei dati INValSI - Sicotem © 1996/ Work in progress - Updated version, Legenda e istruzioni per la lettura dei dati Media: Media aritmetica, valore centrale di una distribuzione somma di tutti i valori di una distribuzione divisa per il numero dei casi. Ad esempio l'altezza media degli alunni di una classe è data dalla somma delle altezze di ciascun alunno diviso il numero totale degli alunni. Mediana: Valore centrale di una distribuzione sopra il quale e sotto il quale ricade la metà dei casi. Ad esempio la mediana dell'altezza degli alunni di una classe è quel valore dell'altezza al di sopra e al di sotto del quale si troverà il 50% dei valori delle altezza degli alunni. Moda: Valore che ricorre più frequentemente in una variabile. Se esistono valori pari merito viene considerato come Moda il valore più basso. Nell'esempio considerato la moda è l'altezza che ricorre più frequentemente tra gli alunni della classe. Minimo: Valore più basso ottenuto per una variabile. Nell'esempio considerato il minimo corrisponde all'altezza minore riscontrata tra gli alunni della classe. Massimo: Valore più alto ottenuto per una variabile. Nell'esempio considerato il massimo corrisponde all'altezza maggiore riscontrata tra gli alunni della classe. Deviazione Standard: È la misura della dispersione dei valori intorno alla Media. Un basso valore della deviazione standard indica che i valori assunti dalla variabile sono concentrati intorno alla media ed esprime omogeneità di dati. Al contrario, un alto valore della deviazione standard indica che i valori assunti dalla variabile si discostano molto dalla media ed esprime disomogeneità di dati. Nell'esempio considerato se l'altezza media di una classe è di 170cm si ha un'alto valore della deviazione standard se l'altezza dei singoli alunni si discosta molto dal valore dell'altezza media, quindi troveremo alunni alti 195cm, oppure 150cm. Al contrario si ha un basso valore della deviazione standard se le altezze dei singoli alunni si avvicinano al valore dell'altezza media, quindi avremo alunni alti 175cm oppure 165cm. Errore standard: Indica il campo di variazione di una costante statistica (Media, Mediana, Moda, Deviazione Standard etc) che si ottiene riportand il valore della costante statistica rilevato nel campione all'universo di riferimento. Viene calcolato misurando di quanto il valore della costante statistica presa in esame può variare tra campioni presi dalla stessa distribuzione. Nell'esempio considerato se la classe presa in considerazione è un campione rappresentativo dell'intera scuola, conoscendo la media dell'altezza della classe è possibile conoscere la media l'altezza della scuola con una determinata percentuale di errore (errore standard), quindi se la media delle altezze della classe è 170cm e l'errore standard è del 5%, la media della scuola sarà un valore che oscilla tra 178,5cm e 161,5cm. Quartile: Si definiscono quartili e si indicano con Q1 Q2 e Q3 i tre valori che dividono una distribuzione dei casi in quattro parti uguali. Il primo 25 % dei dati della distribuzione ha come limite superiore il primo quartile, il 50% dei dati hanno come limite il secondo quartile (che e' anche la mediana), e cosi' via. Fasce: Divisione di una distribuzione in intervalli rispetto ai punteggi ottenuti. Bassa: da 0 al primo Quartile incluso; Medio-bassa: dal primo Quartile escluso al secondo Quartile incluso; Medio-alta: dal secondo Quartile escluso al terzo Quartile incluso; Alta: dal terzo Quartile escluso al Punteggio massimo 100 incluso; Top (Fascia di eccellenza):dal novantesimo percentile incluso al Punt.o massimo 100 incluso. Percentile: Si definiscono percentili e si indicano con P1 P2, P3 ... P99 i novantanove valori che dividono una distribuzione dei casi in cento parti uguali. Il primo 5 % dei dati della distribuzione ha come limite superiore il percentile P5, il 50% dei dati hanno come limite il percentile P50 (che e' anche la mediana), e cosi' via. Punteggi normalizzati: Un punteggio è normalizzato quando si esprimono i risultati in centesimi. Ad esempio se in un test composto da 20 domande vengono date 15 risposte corrette, in media si è risposto correttamente ai 3/4 delle domande, il dato che si troverà è i 3/4 di 100, ossia 75%. Punteggi = ' - ' Il punteggio non è calcolato per mancanza di casi Attenzione: Relativamente ai riferimenti per regione si rammenta che, per il Trentino-Alto Adige provincia di Bolzano, i valori riportati comprendono tutti e tre i gruppi linguistici (italiano, ladino, tedesco)
 che si ottiene riportand il valore della costante statistica rilevato nel campione all universo di riferimento. Viene calcolato misurando di quanto il valore della costante statistica presa in esame può variare tra campioni presi dalla stessa distribuzione. Nell esempio considerato se la classe presa in considerazione è un campione rappresentativo dell intera scuola, conoscendo la media dell altezza della classe è possibile conoscere la media l altezza della scuola con una determinata percentuale di errore (errore standard), quindi se la media delle altezze della classe è 170cm e l errore standard è del 5%, la media della scuola sarà un valore che oscilla tra 178,5cm e 161,5cm. Quartile: Si definiscono quartili e si indicano con Q1 Q2 e Q3 i tre valori che dividono una distribuzione dei casi in quattro parti uguali. Il primo 25 % dei dati della distribuzione ha come limite superiore il primo quartile, il 50% dei dati hanno come limite il secondo quartile (che e anche la mediana), e cosi via. Fasce: Divisione di una distribuzione in intervalli rispetto ai punteggi ottenuti. Bassa: da 0 al primo Quartile incluso; Medio-bassa: dal primo Quartile escluso al secondo Quartile incluso; Medio-alta: dal secondo Quartile escluso al terzo Quartile incluso; Alta: dal terzo Quartile escluso al Punteggio massimo 100 incluso; Top (Fascia di eccellenza):dal novantesimo percentile incluso al Punt.o massimo 100 incluso. Percentile: Si definiscono percentili e si indicano con P1 P2, P3 ... P99 i novantanove valori che dividono una distribuzione dei casi in cento parti uguali. Il primo 5 % dei dati della distribuzione ha come limite superiore il percentile P5, il 50% dei dati hanno come limite il percentile P50 (che e anche la mediana), e cosi via. Punteggi normalizzati: Un punteggio è normalizzato quando si esprimono i risultati in centesimi. Ad esempio se in un test composto da 20 domande vengono date 15 risposte corrette, in media si è risposto correttamente ai 3/4 delle domande, il dato che si troverà è i 3/4 di 100, ossia 75%. Punteggi = - Il punteggio non è calcolato per mancanza di casi. Attenzione: Relativamente ai riferimenti per regione si rammenta che, per il Trentino-Alto Adige provincia di Bolzano, i valori riportati comprendono tutti e tre i gruppi linguistici (italiano, ladino, tedesco)")
4
Punteggi ottenuti dagli studenti
CLASSE II PRIMARIA Punteggi ottenuti dagli studenti Media Deviazione Standard P m P Max Moda Mediana I T A L N O MILANO 86,01 15,51 100 100 92,86 Lombardia 85,71 15,58 100 100 92,86 Nord Ovest 86,04 15,58 100 100 92,86 N0RD EST CENTRO 86,48 87,68 15,25 15,26 100 100 92,86 SUD E ISOLE TOTALE 88,33 87,62 15,96 15,29 100 100 92,86

5
Punteggi ottenuti dagli studenti
CLASSE II PRIMARIA Punteggi ottenuti dagli studenti Media Deviazione Standard P m P Max Moda Mediana M A T E I C MILANO 67,60 21,16 100 81,25 68,75 Lombardia 66,81 21,37 100 81,25 68,75 Nord Ovest 68,73 21,28 100 81,25 68,75 NORD EST CENTRO 71,10 74,86 20,34 20,09 100 87,50 93,75 75,00 81,25 SUD E ISOLE TOTALI 78,48 74,34 20,70 20,89 100 100 87,50 81,25

6
Punteggi ottenuti dagli studenti
CLASSE II PRIMARIA Punteggi ottenuti dagli studenti Media Deviazione Standard P m P Max Moda Mediana MILANO 70,26 21,65 100 80 80 S C I E N Z Lombardia 69,87 21,51 100 80 70 Nord Ovest 70,99 21,61 100 80 70 NORD EST CENTRO 71,59 75,84 21,37 21,36 100 80 100 80 70 SUD E ISOLE TOTALI 80,61 75,89 20,98 21,58 100 100 90 80

7
Punteggi ottenuti dagli studenti
CLASSE IV PRIMARIA Punteggi ottenuti dagli studenti Media Deviazione Standard P m P Max Moda Mediana MILANO 61,17 18,41 100 60 63,33 I T A L N O LOMBARDIA 60,77 18,41 100 70 63,33 Nord OVEST 61,93 18,68 100 70 63,33 NORD EST CENTRO 63,25 65,36 18,56 19,07 100 73,33 63,33 66,63 SUD E ISOLE TOTALI 66,95 65,23 20,88 19,51 100 90 76,67 70 66,67

8
Punteggi ottenuti dagli studenti
CLASSE IV PRIMARIA Punteggi ottenuti dagli studenti Media Deviazione Standard P m P Max Moda Mediana M A T E I C MILANO 65,63 18,90 100 67,86 67,86 Lombardia 65,76 18,90 100 67,86 67,86 Nord Ovest 67,07 19,14 100 67,86 67.86 NORD EST CENTRO 67,74 71,51 19,06 19,58 100 75,00 85,71 67,86 75,00 SUD E ISOLE TOTALI 75,03 71,82 20,80 20,01 100 96,43 86,43 78,57 75,00

9
Punteggi ottenuti dagli studenti
CLASSE IV PRIMARIA Punteggi ottenuti dagli studenti Media Deviazione Standard P m P Max Moda Mediana MILANO 71,05 17,30 100 78,57 75,00 S C I E N Z Lombardia 70,91 17,37 100 78,57 71,43 Nord Ovest 72,35 17,48 100 78,57 75,00 NORD EST CENTRO 73,38 76,16 17,10 17,74 100 78,57 96,43 75,00 78,57 SUD E ISOLE TOTALI 79,54 76,59 18,91 18,08 100 100 85,71 78,57

10
Punteggi ottenuti dagli studenti
CLASSE I SEC-I GRADO Punteggi ottenuti dagli studenti Media Deviazione Standard P m P Max Moda Mediana MILANO 59,42 17,75 100 66,67 60 I T A L N O Lombardia 59,50 17,56 100 66,67 60 Nord Ovest 59,41 17,71 100 66,67 60 NORD EST CENTRO 59,61 59,54 17,41 18,04 100 66,67 60 SUD E ISOLE TOTALI 54,61 58,05 19,73 18,57 100 63,33 66,67 56,67 60

11
Punteggi ottenuti dagli studenti
CLASSE I SEC-I GRADO Punteggi ottenuti dagli studenti Media Deviazione Standard P m P Max Moda Mediana M A T E I C MILANO 60,00 17,53 100 60,71 60,71 Lombardia 60.54 17,56 100 60,71 60,71 Nord Ovest 60,45 17,71 100 60,71 60,71 NORD EST CENTRO 60,98 60,81 17,54 17,99 100 64,29 6071 60,71 SUD E ISOLE TOTALI 57.59 60,04 19,33 18,40 100 57,14 60,71 57,14 60,71

12
Punteggi ottenuti dagli studenti
CLASSE I SEC-I GRADO Punteggi ottenuti dagli studenti Media Deviazione Standard P m P Max Moda Mediana S C I E N Z MILANO 71,18 16,43 100 82,14 75.00 Lombardia 71,47 16,31 100 82,14 75,00 Nord Ovest 71,44 16,49 100 84,14 75,00 NORD EST CENTRO 72,33 71,56 16,17 16,71 100 82,14 78,57 75,00 SUD E ISOLE TOTALI 68,78 70,67 18,82 17,28 100 82,14 71,43 75.00

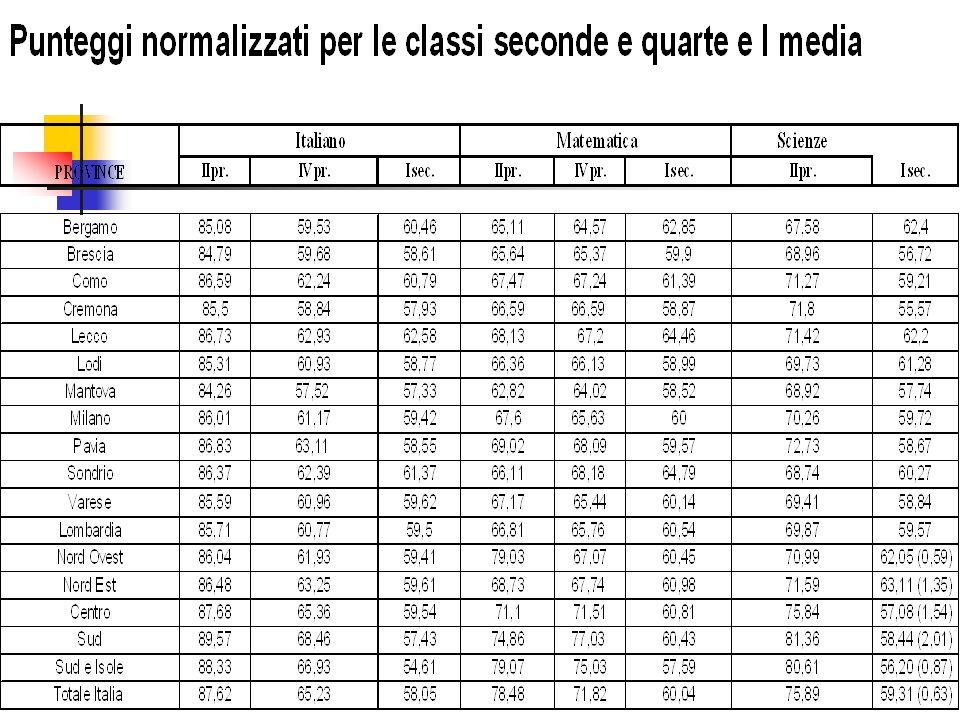
14
PUNTEGGI NORMALIZZATI PER LE CLASSI PRIME E TERZE SUPERIORI

15
L’importanza di Item analysis:
L’analisi degli item permette did misurare la qualità e l’idoneità delle domande somminstrate fornendo il modo di verificare se esse sono appropriate per i candidati nella misurazione delle competenze e abilità. Permette il riutilizzo degli item in situazioni dove la performance dei test si conosce a priori

16
La procedura di raccolta dati
la somministrazione e la raccolta delle risposte può essere compiuta con i prodotti statistici Quando le risposte alle domande a scelta multipla sono conteggiate i risultati con le chiavi di risposta esse possono costituire la base di un’analisi .. Si deve procedere con la registrazione di risposta “1” (corretto) e “0” (sbagliato) per ogni singolo partecipante. Inoltre, il punteggio degli studenti per ogni item (percentuale delle risposte corrette) viene registrato in un tabulato.
 e 0 (sbagliato) per ogni singolo partecipante. Inoltre, il punteggio degli studenti per ogni item (percentuale delle risposte corrette) viene registrato in un tabulato.")
17
Comprensione dei dati E’ importante notare che tre tipi di informazioni sono critici nella comprensione di un esame a scelta multipla: se gli item sono stati troppo difficili o troppo facili; se gli item hanno fatto la differenza tra quegli studenti che veramente conoscevano il materiale e quelli che non lo conoscevano; Se le risposte non corrette in effetti “distraggono” dalla risposta corretta o se invece non hanno alcuna influenza. Si farà riferimento ad alcuni termini in questa guida. Essi comprendono: Il fattore Difficoltà L’Indice di Discriminazione I Coefficienti di Affidabilità Kuder Richardson Ponderazione della Domanda Differenziate La Deviazione Minima, Media e varianza.

18
Il fattore della difficoltà
Il Fattore della Difficoltà di una domanda è dato dalla proporzione dei rispondenti selezionando la risposta giusta a quella domanda. E’ una misura di quanto sia stato difficile rispondere alla domanda. La formula seguente è usata per calcolare questo fattore. D= c/n D – Fattore di Difficoltà c – Numero di risposte corrette n – numero dei rispondenti Più è alto il Fattore di Difficoltà più la domanda è facile. Un valore di 1.0 significa che tutti gli studenti hanno risposto e la domanda può essere facile. La gamma di Difficoltà degli item su un buon test dipende da cosa si desidera conoscere. Se lo scopo di un test è di determinare se gli studenti hanno padroneggiato un’area topica, ci si dovrebbero aspettare dei valori di alta difficoltà. Se lo scopo del test è di discriminare tra diversi livelli di profitto (rendimento) , gli item con valori di difficoltà tra 0,3 e 0,7 sono più efficaci. Il livello ottimale dovrebbe essere 0,5.
 , gli item con valori di difficoltà tra 0,3 e 0,7 sono più efficaci. Il livello ottimale dovrebbe essere 0,5.")
19
L’indice di Discriminazione
L’indice di Discriminazione misura il limite al quale le riposte agli item possono discriminare tra gli individui che hanno un punteggio alto nel test e quelli che ottengono un punteggio basso. Questo è calcolato per ogni risposta. Il valore è calcolato con la seguente formula. DI=(a-b) / n DI – Indice di Discriminazione a – Frequenza di risposta di un quartile elevato (75mo dato percentile) b – Frequenza di risposta di un quartile basso (25mo dato percentile e sotto) n – numero di rispondenti in un quartile elevato (75mo dato percentile e oltre) Un valore negativo significa che gli studenti che ottengono un punteggio basso tendevano a selezionare l’opzione più degli studenti con punteggio più alto. Al contrario, un valore positivo di questo indice significa che gli studenti con punteggio più alto tendevano a selezionare la risposta più spesso. Idealmente, la risposta corretta dovrebbe averne uno positivo. Un valore di 0,0 indica che non c’è differenza tra i due gruppi. La difficoltà di un item può influire sull’indice di discriminazione. Gli item che sono molto facili o molto difficili non ci fanno distinguere molto bene tra gruppi di alto e basso punteggio
 / n. DI – Indice di Discriminazione. a – Frequenza di risposta di un quartile elevato (75mo dato percentile) b – Frequenza di risposta di un quartile basso (25mo dato percentile e sotto) n – numero di rispondenti in un quartile elevato (75mo dato percentile e oltre) Un valore negativo significa che gli studenti che ottengono un punteggio basso tendevano a selezionare l’opzione più degli studenti con punteggio più alto. Al contrario, un valore positivo di questo indice significa che gli studenti con punteggio più alto tendevano a selezionare la risposta più spesso. Idealmente, la risposta corretta dovrebbe averne uno positivo. Un valore di 0,0 indica che non c’è differenza tra i due gruppi. La difficoltà di un item può influire sull’indice di discriminazione. Gli item che sono molto facili o molto difficili non ci fanno distinguere molto bene tra gruppi di alto e basso punteggio.")
20
L’indice di Discriminazione
Su questi item, quasi tutti avranno ottenuto l’item giusto o sbagliato indipendentemente da come essi hanno risposto agli altri item del test. Gli item che mostrano meglio la differenza sono quelli che hanno una difficoltà tra 0,3 e 0,7. Il valore dovrebbe essere in direzione positiva per la corretta risposta e una direzione negativa per una risposta non corretta. Se una risposta ha un valore zero la riposta dovrebbe essere eliminata come scelta.

21
Indici di Kuder Richardson 20
Questa statistica misura l’affidabilità di un test di consistenza inter-item. Un valore più alto indica una relazione forte tra item sul test. Il KR20 è calcolato come segue: N V – SUM (pi qi) KR= --- * N-1 V KR – Kuder Richardson 20 N - Numero di item nel test V - Variazione del punteggio rozzo o deviazione standard elevata al quadrato pi - proporzione di riposte corrette alla domanda i, o (numero di riposte corrette/numero totale di risposte) qi - proporzione di risposte non corrette alla domanda i, o (i-p) Un valore basso indica una relazione debole tra gli item del test. La gamma dei valori da 0 a 1. I test migliori sono all’interno di una gamma che va da .80 a .85. Kunder Richardson 20 sarà sempre maggiore o uguale del Kuder Richardson 21. E’ considerato più accurato del Kuder Richardson 21.
 KR= --- * N-1 V. KR – Kuder Richardson 20. N - Numero di item nel test. V - Variazione del punteggio rozzo o deviazione standard elevata al quadrato. pi - proporzione di riposte corrette alla domanda i, o (numero di riposte corrette/numero totale di risposte) qi - proporzione di risposte non corrette alla domanda i, o (i-p) Un valore basso indica una relazione debole tra gli item del test. La gamma dei valori da 0 a 1. I test migliori sono all’interno di una gamma che va da .80 a .85. Kunder Richardson 20 sarà sempre maggiore o uguale del Kuder Richardson 21. E’ considerato più accurato del Kuder Richardson 21.")
22
Indice di Kuder Richardson 21
Questa statistica fa un calcolo approssimativo della consistenza inter-item. Un valore alto indica una forte relazione tra gli item e un valore basso una relazione più debole. Il mezzo del punteggio medio dell’esame è parte della formula. I valori vanno anche da 0 a 1. La formula è calcolata come segue: N 1-(M(N-M) KR= * N-1 N*V KR – Kuder Richardson 21 N - Numero di item nel test M - Mezzo aritmetico dei punteggi del test V - Variazione dei punteggi rozzi o variazione standard elevata al quadrato Meglio che i test medi abbiano un valore leggermente più basso del KR20.
 KR= ---- * N-1 N*V. KR – Kuder Richardson 21. N - Numero di item nel test. M - Mezzo aritmetico dei punteggi del test. V - Variazione dei punteggi rozzi o variazione standard elevata al quadrato. Meglio che i test medi abbiano un valore leggermente più basso del KR20.")
23
Ponderazione della domanda da differenziare
Un esempio del sistema di ponderazione differenziale potrebbe essere di dare due punti di credito ad alcune domande perché sono molto più difficili o più importanti e un punto di credito ad altre. Le ragioni per cui non usare questo sistema comprendono: Non c’è aumento nell’affidabilità quando si usano ponderazioni differenziali ponderazione differenziale è più efficacie solo nei test brevi (meno di dieci item) Altri Termini per comprendere quando le relazioni Punteggio della media - Punteggio della mediana - il punteggio corrisponde al dato percentile 50mo . Esattamente metà dei punteggi sono più bassi e metà dei più alti. Deviazione standard - la gamma al di sopra o al di sotto il punteggio medio dove la maggioranza dei punteggi mente. Più sono ampi i punteggi, più lo sarà anche la deviazione standard.
 Altri Termini per comprendere quando le relazioni. Punteggio della media - Punteggio della mediana - il punteggio corrisponde al dato percentile 50mo . Esattamente. metà dei punteggi sono più bassi e metà dei più alti. Deviazione standard - la gamma al di sopra o al di sotto il punteggio medio dove la maggioranza dei punteggi mente. Più sono ampi i punteggi, più lo sarà anche la deviazione standard.")
24
Altri item statistici importanti
Idealmente, si dovrebbe volere la “correttezza” di un particolare item in un test in modo tale da associarlo con un punteggio globale (percentuale di tutti gli item a cui si è risposto correttamente). Preso da un angolo diverso, si potrebbero preferire item di test con “risposte frequentemente corrette” da studenti che hanno fatto globalmente bene nel test. Questa associazione tra item di test individuali e performance di test globali è chiamata la correlazione biseriale. Una correlazione più utile è l’esecuzione stimata globale del test ad esclusione dell’ item di test particolare in questione. Questa misura è chiamata la correlazione corretta del punto biseriale di un item di test .
. Preso da un angolo diverso, si potrebbero preferire item di test con risposte frequentemente corrette da studenti che hanno fatto globalmente bene nel test. Questa associazione tra item di test individuali e performance di test globali è chiamata la correlazione biseriale. Una correlazione più utile è l’esecuzione stimata globale del test ad esclusione dell’ item di test particolare in questione. Questa misura è chiamata la correlazione corretta del punto biseriale di un item di test .")
25
L’indice Alpha di Cronbach
La statistica fornisce una misurazione di consistenza interna (affidabilità) di item di test chiamati alpha di Cronbach. Più alta è la correlazione tra gli item, più grande è l’alpha. Alte correlazioni implicano che alti (o bassi) punteggi di una domanda sono associati con alti (o bassi) punteggi su altre domande. Alpha può variare da 0 a 1, indicando che il test è perfettamente affidabile. Inoltre, la computazione dell’ Alpha di Cronbach quando un item particolare è rimosso dalla considerazione è una buona misura del contributo di quell’item all’esecuzione della valutazione dell’intero test. Altre statistiche sono automaticamente generate usando una procedura chiamata Affidabilità (Reliability) (nel risultato, la scala di termine si riferisce alla collezione di tutti gli item di test).
 di item di test chiamati alpha di Cronbach. Più alta è la correlazione tra gli item, più grande è l’alpha. Alte correlazioni implicano che alti (o bassi) punteggi di una domanda sono associati con alti (o bassi) punteggi su altre domande. Alpha può variare da 0 a 1, indicando che il test è perfettamente affidabile. Inoltre, la computazione dell’ Alpha di Cronbach quando un item particolare è rimosso dalla considerazione è una buona misura del contributo di quell’item all’esecuzione della valutazione dell’intero test. Altre statistiche sono automaticamente generate usando una procedura chiamata Affidabilità (Reliability) (nel risultato, la scala di termine si riferisce alla collezione di tutti gli item di test).")
26
L’indice Alpha di Cronbach
(Classe 2° Primaria: Italiano, Matematica e Scienze- rif. Diap 33,34,35). Notate la “Correlazione corretta del totale dell’item”. Questa colonna mostra la correlazione del punto biseriale corretta. Potete vedere che le domande sembrano correlate con l’esecuzione del test generale. Da notare che la domanda 7(it) ha una correlazione negativa con il resto degli items. D’altra parte, gli studenti che tendono ad andare male nei test generalmente tendono a rispondere a questa domanda correttamente. Questo non è un risultato desiderato. Notate il valore di alpha nella colonna intitolata “Alpha se Item è eliminato”. Se la domanda 7(it) è eliminata dalla tabella, la statistica Alpha sale a , con questa prospettiva, la domanda 7 ha bisogno di essere esaminata criticamente e forse riscritta.
. Notate la Correlazione corretta del totale dell’item . Questa colonna mostra la correlazione del punto biseriale corretta. Potete vedere che le domande sembrano correlate con l’esecuzione del test generale. Da notare che la domanda 7(it) ha una correlazione negativa con il resto degli items. D’altra parte, gli studenti che tendono ad andare male nei test generalmente tendono a rispondere a questa domanda correttamente. Questo non è un risultato desiderato. Notate il valore di alpha nella colonna intitolata Alpha se Item è eliminato . Se la domanda 7(it) è eliminata dalla tabella, la statistica Alpha sale a , con questa prospettiva, la domanda 7 ha bisogno di essere esaminata criticamente e forse riscritta.")
27
Administrator:Click su collegamento ipertestuale
Per tornare alla pagina successiva della presentazione chiudere l’explorer Reliability of items in relation con "prova di italiano” – classi seconde

28
Administrator:Click su collegamento ipertestuale
Per tornare alla pagina successiva della presentazione chiudere l’explorer Reliability of items in relation con "prova di matematica” – classi seconde

29
Administrator:Click su collegamento ipertestuale
Per tornare alla pagina successiva della presentazione chiudere l’explorer Reliability of items in relation con "prova di scienze”- classi seconde

30
Analisi delle risposte errate
In una domanda a scelta multipla, le scelte sbagliate sono chiamate “distracters” (“risposte errate”). Quando create le domande dei test, dovete considerare: Una percentuale di studenti dovrebbe selezionare ogni distrattore (risposta errata) (al posto della risposta giusta) o il distrattore non è efficiente. Se una percentuale troppo grande di studenti seleziona un particolare distrattore , ci potrebbe essere un’ambiguità nella formulazione della domanda o nella formulazione di un particolare distrattore. Un distracttore ha valore se la percentuale di studenti che lo seleziona si differenzia a seconda della loro produzione globale del test. Un buon distrattore è quello che è selezionato da pochi studenti che erano nel terzo gruppo di alto livello della classe, ma scelto da molti studenti nel terzo gruppo di basso livello.
. Quando create le domande dei test, dovete considerare: Una percentuale di studenti dovrebbe selezionare ogni distrattore (risposta errata) (al posto della risposta giusta) o il distrattore non è efficiente. Se una percentuale troppo grande di studenti seleziona un particolare distrattore , ci potrebbe essere un’ambiguità nella formulazione della domanda o nella formulazione di un particolare distrattore. Un distracttore ha valore se la percentuale di studenti che lo seleziona si differenzia a seconda della loro produzione globale del test. Un buon distrattore è quello che è selezionato da pochi studenti che erano nel terzo gruppo di alto livello della classe, ma scelto da molti studenti nel terzo gruppo di basso livello.")
31
conclusione L’analisi degli item è una serie di procedure disponibili estremamente utile ai professionisti dell’insegnamento. SPSS è uno degli strumenti di statistica potente per misurare l’analisi degli item e un modo ideale per gli educatori per creare, valutare e validare i test di apprendimento somministrate alle classi. L’analisi degli item permette agli istruttori di migliorare gli esercizi in classe e agli esecutori dei test di migliorare i loro esami.

32
Fine lavoro

33
Bibliografia Dati della Lombardia INValSI -RNSIF-as 2004/2005
Quantitative data analysis with SPSS di Alan Bryman,D. Cramer2003 Data Analysis Using SPSS-Beginner’s Guide J. Foster 1999 Adventures in Social Research:Data Analysis using SPSS di Earl Babbie , Fred Halley, J. Zaino 2003 Common Analysis of Repeated Measures: M. J. Crowder 1990 Common Correlation and Reliability Analysis with SPSS di R. A. Yaffee

Presentazioni simili





>")













