Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
Corso di Laurea Specialistica in Ingegneria Gestionale Sistemi Informativi per le decisioni a.a. 2008-2009 Waikato Environment for Knowledge Analysis Data preprocessing e regole associative Cicolella Claudio, Minetti Elena, Triscari Dario

2
Weka Formato.arff Preprocess Non supervisionati Attributi: Discretize Remove ReplaceMissingValues Normalize Standardize Istanze: Resample Supervisionati Attributi: Discretize AttributeSelection Istanze: Resample Associate Apriori Argomenti

3
Weka Formato.arff Preprocess Non supervisionati Attributi: Discretize Remove ReplaceMissingValues Normalize Standardize Istanze: Resample Supervisionati Attributi: Discretize AttributeSelection Istanze: Resample Associate Apriori Argomenti

4
Weka

5
Weka: preprocess e associate Preprocess: permette di caricare e modificare i dati su cui eseguire le varie elaborazioni Asssociate: permette l’elaborazione e valutazione di regole di associazione Weka

7
Formato.arff Preprocess Non supervisionati Attributi: Discretize Remove ReplaceMissingValues Normalize Standardize Istanze: Resample Supervisionati Attributi: Discretize AttributeSelection Istanze: Resample Associate Apriori Argomenti

8
Sezione Header Sezione Data ARFF (Attribute Relationship File Format) Formato.arff
 Formato.arff")
9
Weka Formato.arff Preprocess Non supervisionati Attributi: Discretize Remove ReplaceMissingValues Normalize Standardize Istanze: Resample Supervisionati Attributi: Discretize AttributeSelection Istanze: Resample Associate Apriori Argomenti

10
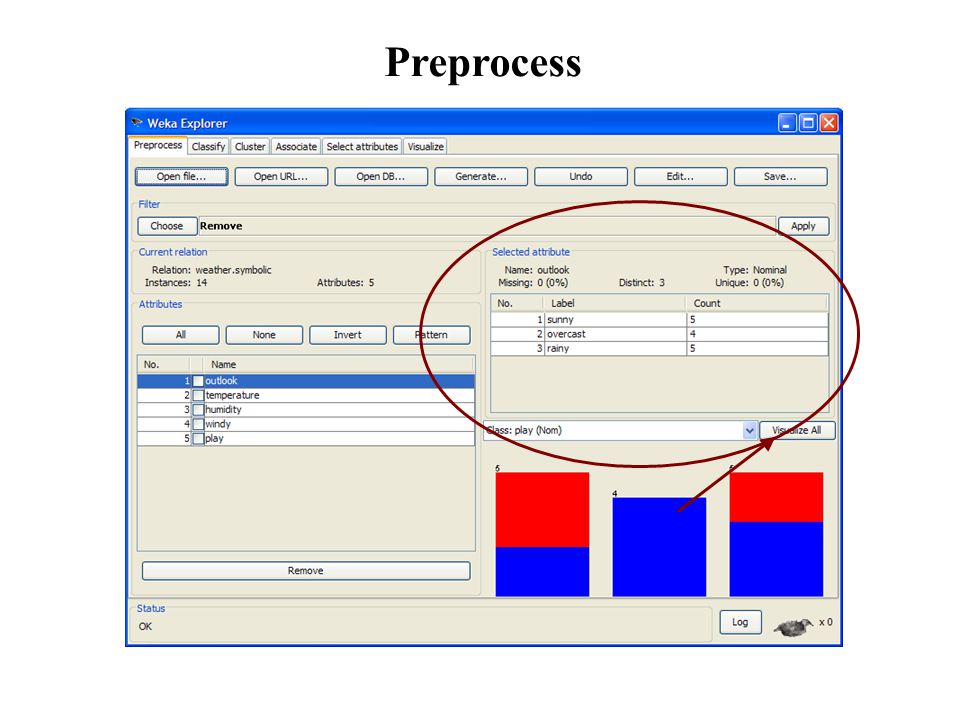
Preprocess

13
Filtri

14
Supervisionati: esiste un attributo speciale, il class attribute, che viene usato per guidare le operazioni di filtraggio Non supervisionati: tratta tutti gli attributi allo stesso modo Filtri

15
Attribute: operano su un singolo o più attributi selezionati Istanze: operano a livello di tuple prendendo in considerazione la totalità degli attributi Filtri

16
Weka Formato.arff Preprocess Non supervisionati Attributi: Discretize Remove ReplaceMissingValues Normalize Standardize Istanze: Resample Supervisionati Attributi: Discretize AttributeSelection Istanze: Resample Associate Apriori Argomenti

17
Questo tipo di filtro serve per convertire gli attributi numerici in etichette stringa. attributeIndices: permette di selezionare l’attributo o gli attributi da discretizzare bins: permette di scegliere il numero di bin makeBinary: se settato “true”rende gli attributi finali in formato binario useEqualFrequency: se settato “true”verranno formati bin di uguale frequenza invece che di uguale larghezza findNumBins: ottimizza il numero di bin di uguale larghezza utilizzando il metodo leave-one-out; non è applicabile con useEqualFrequency desiredWeightOfInsta ncesPerInterval: larghezza dell’intervallo nella divisione in bin di uguale profondità ignoreClass: se settato “true” ignora la classificazione prima di applicare il filtro invertSelection: se settato “true” il filtro verrà applicato a tutti i campi tranne a quello/i selezionato/i nel box attributeindices Filtri non supervisionati : Discretize

18
attributeIndices: permette di selezionare l’attributo da rimuovere invertSelection: se settato “true” il filtro verrà applicato a tutti i campi tranne a quello/i selezionato/i nel box attributeindices Filtri non supervisionati : Remove Questo tipo di filtro serve per eliminare dal dataset un attributo con tutti i relativi valori.

19
ignoreClass: se settato “true” ignora la classificazione prima di applicare il filtro Filtri non supervisionati : ReplaceMissingValue Questo tipo di filtro serve per sostituire i valori mancanti all’interno del dataset con la moda nel caso di dati categorici e con la media nel caso di dati numerici.

20
ignoreClass: se settato “true” ignora la classificazione prima di applicare il filtro scale: fattore di scala translation: fattore di scala Filtri non supervisionati : Normalize Questo tipo di filtro agisce sui range di variazione degli attributi uniformandoli a [0,1] (default) o ad altri intervalli.
![ignoreClass: se settato true ignora la classificazione prima di applicare il filtro scale: fattore di scala translation: fattore di scala Filtri non supervisionati : Normalize Questo tipo di filtro agisce sui range di variazione degli attributi uniformandoli a [0,1] (default) o ad altri intervalli.](http://images.slideplayer.it/16/5202648/slides/slide_20.jpg "ignoreClass: se settato true ignora la classificazione prima di applicare il filtro scale: fattore di scala translation: fattore di scala Filtri non supervisionati : Normalize Questo tipo di filtro agisce sui range di variazione degli attributi uniformandoli a [0,1] (default) o ad altri intervalli.")
21
μ= valor medio statistico σ= deviazione standard ignoreClass: se settato “true” ignora la classificazione prima di applicare il filtro Filtri non supervisionati : Standardize Questo tipo di filtro applica un altro tipo di normalizzazione ottenendo che gli attributi numerici siano distribuiti con valor medio nullo e deviazione standard unitaria.

22
invertSelection: permette di invertire la selezione di istanze (solo se sampling senza replacement) NoReplacement : permette di disabilitare la sostituzione dei valori originali randomSeed: permette di scegliere il “seme” alla base della generazione dei numeri casuali sampleSizePercent: permette di scegliere la percentuale del data set originale fornita in output Filtri non supervisionati : Resample Questo tipo di filtro attua una riduzione verticale producendo un sottoinsieme casuale delle istanze del data set sia sostituendo i valori originale che mantenendo quelli già presenti.
 NoReplacement : permette di disabilitare la sostituzione dei valori originali randomSeed: permette di scegliere il seme alla base della generazione dei numeri casuali sampleSizePercent: permette di scegliere la percentuale del data set originale fornita in output Filtri non supervisionati : Resample Questo tipo di filtro attua una riduzione verticale producendo un sottoinsieme casuale delle istanze del data set sia sostituendo i valori originale che mantenendo quelli già presenti.")
23
Weka Formato.arff Preprocess Non supervisionati Attributi: Discretize Remove ReplaceMissingValues Normalize Standardize Istanze: Resample Supervisionati Attributi: Discretize AttributeSelection Istanze: Resample Associate Apriori Argomenti

24
attributeIndices: permette di selezionare l’attributo o gli attributi da discretizzare makeBinary: se settato “true”rende gli attributi finali in formato binario invertSelection: se settato “true” il filtro verrà applicato a tutti i campi tranne a quello/i selezionato/i nel box attributeindices Filtri supervisionati : Discretize Questo tipo di filtro serve per convertire gli attributi numerici in etichette stringa.

25
Filtri supervisionati : AttributeSelection Questo tipo di filtro permette l’accesso alle funzioni di selezione di attributi così come nella sezione Select attributes. evaluator: permette di selezionare il parametro su cui effettuare la valutazione search: metodo attraverso cui effettuare la valutazione numToselect: permette di scegliere numero di attributi da selezionare startSet: permette di selezionare un elenco di attributi da ignorare threshold: valore soglia del valutatore

26
biasToUniformClass: permette di settare un valore che varia da 0 (non variando la distribuzione) a 1 (rendendo la distribuzione uniforme) invertSelection: permette di invertire la selezione di istanze (solo se sampling senza replacement) NoReplacement : permette di disabilitare la sostituzione dei valori originali randomSeed: permette di scegliere il “seme” alla base della generazione dei numeri casuali sampleSizePercent: permette di scegliere la percentuale del data set originale fornita in output Filtri supervisionati : Resample Questo tipo di filtro produce un sottoinsieme di valori casuali del data set originale con o senza replacement. In aggiunta rispetto alla versione non supervisionata, tenta di mantenere la distribuzione dell’attributo classe o di correggerne il bias.

27
Weka Formato.arff Preprocess Non supervisionati Attributi: Discretize Remove ReplaceMissingValues Normalize Standardize Istanze: Resample Supervisionati Attributi: Discretize AttributeSelection Istanze: Resample Associate Apriori Argomenti

28
Weka: preprocess e associate Associate

30
Alcuni esempi: Apriori: algoritmo Apriori per le regole associative PredictiveApriori: algoritmo Apriori che trova regole di associazione ordinate per accuratezza nella predizione; questo parametro è ricavato da una combinazione di confidenza e supporto Tertius: algoritmo a conferma guidata durante la scoperta di regole di associazione Algoritmi per regole associative

31
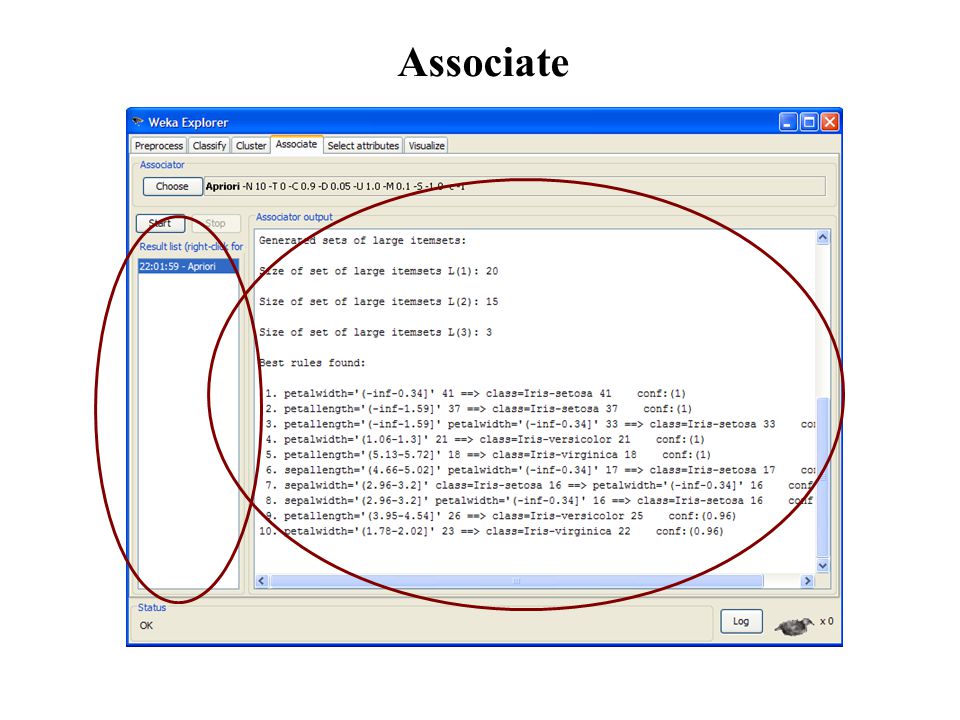
Come funziona Apriori in Weka ? Apriori in Weka comincia con il supporto minimo all'estremo superiore e diminuisce il supporto di Delta ad ogni iterazione. Si arresta quando è stato generato il numero richiesto di regole, oppure è stato raggiunto l'estremo inferiore per il supporto minimo. Regole associative: Apriori

32
car: settato “true” vengono generate regole associative dove il class attribute è conseguente classIndex: indice del class attribute; se settato a -1 l’ultimo attributo è preso come class attribute delta: permette di settare il valore delta metricType: permette di scegliere la metrica secondo cui ordinare e selezionare i risultati lowerBoundMinSupp ort: lower bound per il supporto Regole associative: Apriori

33
Data la regola L => R: confidence = Pr(L,R) / Pr(L) lift = Pr(L,R) / Pr(L)*Pr(R) leverage = Pr(L,R) - Pr(L)*Pr(R) conviction = Pr(L)*Pr(not R) / Pr(L,R) Apriori: metricType
 / Pr(L) lift = Pr(L,R) / Pr(L)*Pr(R) leverage = Pr(L,R) - Pr(L)*Pr(R) conviction = Pr(L)*Pr(not R) / Pr(L,R) Apriori: metricType")
34
numRules: permette di selezionare il numero di regole che si vuole vengano generate removeAllMissingCols: rimuove dal dataset le colonne con tutti i valori mancanti. upperBoundMinSup port: upper bound per il supporto minimo minMetric: considera solo le regole che superano questo valore outputItemSets: se settato “true”vengono mostrati gli itemset frequenti verbose: se abilitato esegue l’algoritmo in modalità verbose Regole associative: Apriori

35
Associate

Presentazioni simili