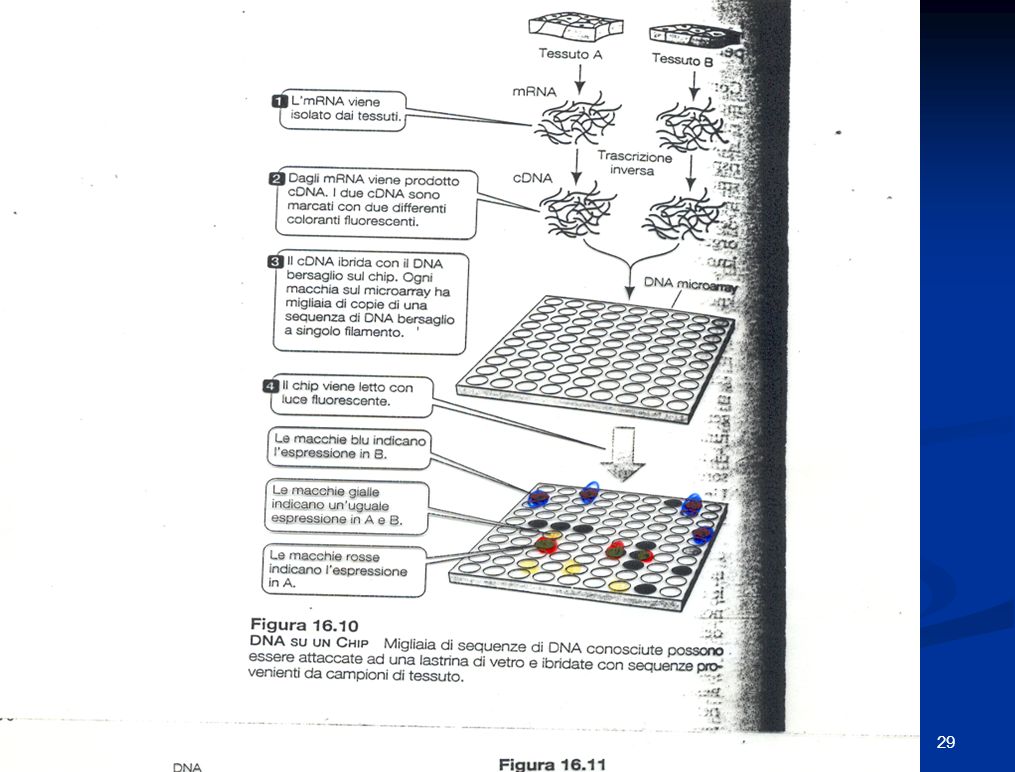
Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
c). Chimica del DNA i). Forze che influenzano la stabilità della doppia elica del DNA interazioni idrofobiche - stabilizzano dentro idrofobiche e fuori idrofiliche relativamente deboli ma aggiuntive forze di Van de Waals legami idrofobi – stabilizzano legami idrogeno - stabilizzano relativamente deboli ma aggiungono e facilitano impilamento interazioni elettrostatiche - destabilizzano contribuiti primariamente dai fosfati (negativi) interessano interazioni intrafilamento e interfilamento repulsione può essere neutralizzata da cariche positive (es, ioni Na+ o proteine cariche positivamente) Tre tipi di forze contribuiscono a mantenere la stabilità della doppia elica di DNA: 1) interazioni idrofobiche per cui l’interno è idrofobico e l’esteno con I fosfati idrofilico 2) legami idrofobi (sono quelli per cui gruppi idrofobi tendono ad unirsi a causa dell’acqua),, e 3) legami idrogeno. Le coppie di basi all’interno della molecola di DNA creano un ambiente idrofobico, con i fosfati carichi negativamente lungo la spina dorsale essendo esposti al solvente. Così, in un ambiente acquoso, la struttura a doppio filamento è stabilizzata dall’interno idrofobico. I reagenti che solubilizzano le basi del DNA (es. metanolo) destabilizzano la doppia elica. Legami idrofobi e legami idrogeno sono relativamente deboli ma aggiuntivi. I reagenti che distruggono i legami idrogeno [es., formamide, urea, e soluzioni con pH molto basso (pH <2.3) o molto alto (pH >10)] destabilizzano la doppia elica. La repulsione elettrostatica mediante fosfati carichi negativamente lungo la spina dorsale del DNA destabilizzano la doppia elica. Per es, se i fosfati sono non protetti, come quando il DNA è disciolto in acqua distillata, i filamenti del DNA potrebbero separarsi a temperatura ambiente. Neutralizzando queste cariche negative mediante addizione di NaCl (con cui contribuiscono ioni sodio carichi positivamente) alla soluzione di DNA, si potrebbe prevenire la separazione dei filamenti. Nella cellula, i fosfati reagiscono anche con ioni magnesio carichi positivamente e con proteine basiche cariche positivamente.
 interessano interazioni intrafilamento e interfilamento. repulsione può essere neutralizzata da cariche positive. (es, ioni Na+ o proteine cariche positivamente) Tre tipi di forze contribuiscono a mantenere la stabilità della doppia elica di DNA: 1) interazioni idrofobiche per cui l’interno è idrofobico e l’esteno con I fosfati idrofilico 2) legami idrofobi (sono quelli per cui gruppi idrofobi tendono ad unirsi a causa dell’acqua),, e 3) legami idrogeno. Le coppie di basi all’interno della molecola di DNA creano un ambiente idrofobico, con i fosfati carichi negativamente lungo la spina dorsale essendo esposti al solvente. Così, in un ambiente acquoso, la struttura a doppio filamento è stabilizzata dall’interno idrofobico. I reagenti che solubilizzano le basi del DNA (es. metanolo) destabilizzano la doppia elica. Legami idrofobi e legami idrogeno sono relativamente deboli ma aggiuntivi. I reagenti che distruggono i legami idrogeno [es., formamide, urea, e soluzioni con pH molto basso (pH <2.3) o molto alto (pH >10)] destabilizzano la doppia elica. La repulsione elettrostatica mediante fosfati carichi negativamente lungo la spina dorsale del DNA destabilizzano la doppia elica. Per es, se i fosfati sono non protetti, come quando il DNA è disciolto in acqua distillata, i filamenti del DNA potrebbero separarsi a temperatura ambiente. Neutralizzando queste cariche negative mediante addizione di NaCl (con cui contribuiscono ioni sodio carichi positivamente) alla soluzione di DNA, si potrebbe prevenire la separazione dei filamenti. Nella cellula, i fosfati reagiscono anche con ioni magnesio carichi positivamente e con proteine basiche cariche positivamente.")
2
5’ 3’ Fosfati idrofobici Fosfati idrofilici 3’ 5’ Regione del
Nella doppia elica del DNA l’interno idrofobico e l’esterno idrofilico. 3’ 5’ Regione del core idrofobica

3
Interactions Sovrapposte
Cariche repulsione Questa diapositiva mostra interazioni tra basi sovrapposte e cariche di repulsione nella doppia elica. Cariche di repulsione

4
Le nucleasi idrolizzano i legami fosfodiesterei
Esonucleasi tagliano i nucleotidi terminali 5’ 3’ es, esonucleasi proofreading Endonucleasi tagliano interna mente e possono tagliare su entrambi i lati del fosfato lasciando estremità 5’ fosfato o 3’ fosfato in dipendenza del- la particolare endonucleasi. Le desossiribonucleasi (o DNAsi) sono enzimi che tagliano legami fosfodiesterei. Alcuni sono usati a scopo costruttivo, come ad es. correzione di bozze durante la replicazione del DNA, mentre altri sono usati per degradare il DNA. Ci sono 2 classi di Dnasi: esonucleasi e endonucleasi. Le esonucleasi rimuovono solo il nucleotide terminale, mentre le endonucleasi tagliano dovunque entro la doppia elica del DNA. es, endonucleasi restrizione 3’ 5’
 sono enzimi che tagliano legami fosfodiesterei. Alcuni sono usati a scopo costruttivo, come ad es. correzione di bozze durante la replicazione del DNA, mentre altri sono usati per degradare il DNA. Ci sono 2 classi di Dnasi: esonucleasi e endonucleasi. Le esonucleasi rimuovono solo il nucleotide terminale, mentre le endonucleasi tagliano dovunque entro la doppia elica del DNA. es, endonucleasi restrizione. 3’ 5’")
5
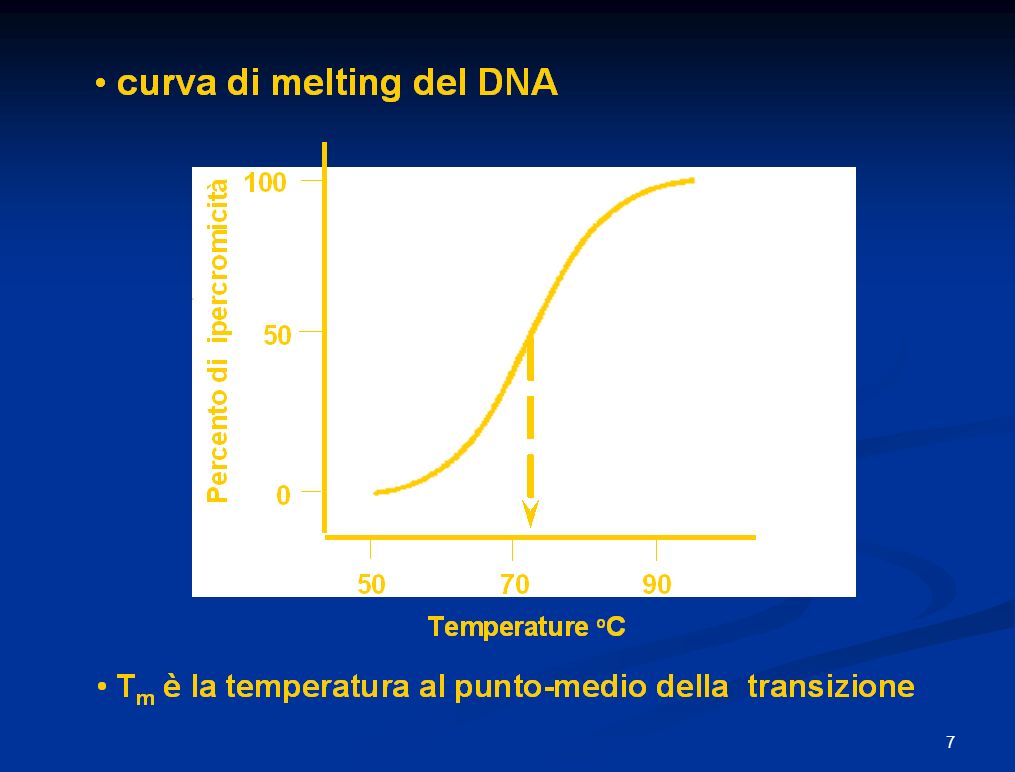
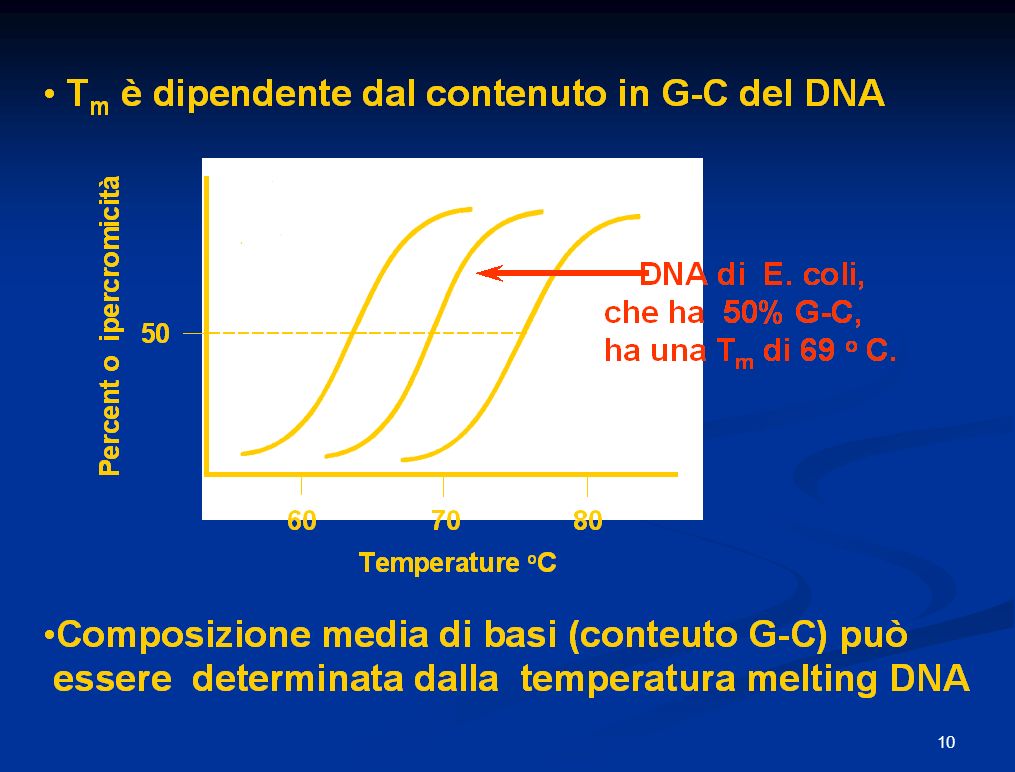
Poiché la coppia CG è unita da 3 legami ad idrogeno, il punto di fusione cioè la temp.alla quale metà del campione di DNA non è legato da legami idrogeno è proporzionale al contenuto di CG. Il DNA umano che ha in media 60% di AT e 40% di CG presenta una TM di87°C, mentre i procarioti che hanno 50% di CG hanno Tm 69°C. In media ogni coppia aggiuntiva di CG determina un aumento di 0,4 °C di Tm.

6
ii). Denaturazione del DNA
Separazione dei filamenti e formazione di un singolo-filamento avvolto a caso DNA a doppio-filamento Regioni ricche A-T denaturano prima pH estremi o alte temperature Le forze che stabilizzano la doppia elica del DNA possono essere vinte mediante riscaldamento del DNA in soluzione o trattando questo con pH molto alti o molto bassi (basso pH potrebbe danneggiare il Dna, mentre alto pH potrebbe semplicemente separare le catene polinucleotidiche). Quando i filamenti del DNA si separano, il DNA è detto denaturato (quando alte temperature sono usate per denaturare il DNA, il DNA è detto essere fuso). Poichè alcune delle forze che stabilizzano l’elica del DNA sono costituite da interazioni tra appaiamento di basi, e poichè le coppie di basi A-T hanno solo 2 legami idrogeno in contrasto con le coppie G-C che hanno 3 legami idrogeno, le regioni del duplex di DNA che sono ricche in A-T denaturano prima. Una volta che la denaturazione è iniziata, c’è uno svolgimento cooperativo della doppia elica che alla fine si conclude in una completa separazione dei filamenti. Svolgimento cooperativo dei filamenti del DNA
. Quando i filamenti del DNA si separano, il DNA è detto denaturato (quando alte temperature sono usate per denaturare il DNA, il DNA è detto essere fuso). Poichè alcune delle forze che stabilizzano l’elica del DNA sono costituite da interazioni tra appaiamento di basi, e poichè le coppie di basi A-T hanno solo 2 legami idrogeno in contrasto con le coppie G-C che hanno 3 legami idrogeno, le regioni del duplex di DNA che sono ricche in A-T denaturano prima. Una volta che la denaturazione è iniziata, c’è uno svolgimento cooperativo della doppia elica che alla fine si conclude in una completa separazione dei filamenti. Svolgimento cooperativo. dei filamenti del DNA.")
8
regioni ricche in A-T fondono prima, seguite da regioni
Micrografia elettronica di DNA parzialmente fuso DNA a doppio-filamento, ricco in G-C che non è ancora fuso Questa diapositiva mostra il calco di DNA di una micrografia elettronica che è solo parzialmente fusa. Le regioni più spesse sono a doppio filamento e probabilmente più ricche in G-C. Le regioni ricche in A-T sono più propense alla denaturazione, e come si vede, formano bolle a singolo filamento. Regioni di DNA ricche A-T fondono (si separano) in una bolla a singolo- filamento regioni ricche in A-T fondono prima, seguite da regioni ricche in G-C
 in una bolla a singolo- filamento. regioni ricche in A-T fondono prima, seguite da regioni. ricche in G-C.")
9
Ipercromicità Singolo-filamento Assorbanza Doppio-filamento 220 260
Quando una soluzione di DNA a doppio filamento è posta in una cuvetta dello spettrofotometro ed è determinata l’assorbanza del DNA attraverso lo spettro elettromagnetico, questa soluzione caratteristicamente mostra un massimo di assorbanza a 260 nm (nella regione UV dello spettro). Se la stessa soluzione di DNA è fusa, l’assorbanza a 260 nm aumenta approssimativamente del 40%. Questa proprietà è chiamata “ipercromicità”. Il cambiamento ipercromico è dovuto al fatto che le basi non sovrapposte assorbono più luce rispetto a quelle sovrapposte. 220 260 300 L’assorbanza a 260 nm di una soluzione di DNA aumenta quando la doppia elica è separata in singoli filamenti.
. Se la stessa soluzione di DNA è fusa, l’assorbanza a 260 nm aumenta approssimativamente del 40%. Questa proprietà è chiamata ipercromicità . Il cambiamento ipercromico è dovuto al fatto che le basi non sovrapposte assorbono più luce rispetto a quelle sovrapposte L’assorbanza a 260 nm di una soluzione di DNA aumenta. quando la doppia elica è separata in singoli filamenti.")
13
a). Complessità del DNA cromosomico
DNA riassociazione (rinaturazione) DNA a doppio-filamento Denaturazione, DNA a singolo-filamento Più veloce, reazione “zippering” per formare lunghe molecole di DNA a doppio filamento La denaturazione del DNA a doppia elica produce DNA a singolo filamento. La reazione opposta (la formazione di DNA a doppia elica) può avvenire se i filamenti complementari di DNA sono incubati in condizioni che pruomovono la rinaturazione (riassociazione).Questo processo di rinaturazione coinvolge 2 tappe.La prima tappa è più lenta,è una reazione a velocità-limitante, in cui i filamenti complementari collidono casualmente originando un evento iniziale di nucleazione costituito da circa una decina di basi azotate complementari. Poichè i due filamenti reagenti sono alla stessa concentrazione in soluzione, la reazione è di secondo ordine, con una velocità di reazione che può essere definita come costante di velocità di secondo ordine, K2 . Una volta che questo nucleo di rinaturazione si è formato, la seconda tappa è più veloce, la parte rimanente della molecola si riavvolge rapidamente ed è costituita dall’interazione “zippering” delle coppie di basi nucleotidiche adiacenti. La reazione di rinaturazione è una reazione di secondo ordine perchè richiede l’interazione fra 2 molecole: a parità di lunghezza delle molecole e delle condizioni di incubazione, la velocità di rinaturazione è tanto maggiore quanto più semplice è la sequenza delle eliche complementari. Così per es. Un DNA formato solo di poliA su un’elica e di poliT sull’altra si rinatura più rapidamente di un DNA in cui le 2 eliche hanno sequenze complementari più complesse. La complessità del DNA è in funzione di quante paia di basi esso possiede.In altre parole, un DNA a bassa complessità consiste di poche centinaia di paia di basi, in contrasto ad un alta complessità del DNA che contiene milioni di paia di basi. Sequenze a bassa complessità sono in grado di trovarsi tra loro più velocemente durante una reazione di rinaturazione, piuttosto che le sequenze ad alta complessità, poichè le sequenze a bassa complessità devono svolgere poche collisioni per cercare un partnerdi base con cui appaiarsi. Così, la velocità della reazione di rinaturazione è in funzione della complessità del DNA. In altre parole,la complessità del DNA può essere determinata misurando la costante di velocità di riassociazione di secondo-ordine. k2 Lenta, processo di secondo-ordine a velocità limitante, per trovare sequenze di basi complementari
 DNA a doppio-filamento. Denaturazione, DNA a. singolo-filamento. Più veloce, reazione. zippering per. formare lunghe. molecole di. DNA a doppio. filamento. La denaturazione del DNA a doppia elica produce DNA a singolo filamento. La reazione opposta (la formazione di DNA a doppia elica) può avvenire se i filamenti complementari di DNA sono incubati in condizioni che pruomovono la rinaturazione (riassociazione).Questo processo di rinaturazione coinvolge 2 tappe.La prima tappa è più lenta,è una reazione a velocità-limitante, in cui i filamenti complementari collidono casualmente originando un evento iniziale di nucleazione costituito da circa una decina di basi azotate complementari. Poichè i due filamenti reagenti sono alla stessa concentrazione in soluzione, la reazione è di secondo ordine, con una velocità di reazione che può essere definita come costante di velocità di secondo ordine, K2 . Una volta che questo nucleo di rinaturazione si è formato, la seconda tappa è più veloce, la parte rimanente della molecola si riavvolge rapidamente ed è costituita dall’interazione zippering delle coppie di basi nucleotidiche adiacenti. La reazione di rinaturazione è una reazione di secondo ordine perchè richiede l’interazione fra 2 molecole: a parità di lunghezza delle molecole e delle condizioni di incubazione, la velocità di rinaturazione è tanto maggiore quanto più semplice è la sequenza delle eliche complementari. Così per es. Un DNA formato solo di poliA su un’elica e di poliT sull’altra si rinatura più rapidamente di un DNA in cui le 2 eliche hanno sequenze complementari più complesse. La complessità del DNA è in funzione di quante paia di basi esso possiede.In altre parole, un DNA a bassa complessità consiste di poche centinaia di paia di basi, in contrasto ad un alta complessità del DNA che contiene milioni di paia di basi. Sequenze a bassa complessità sono in grado di trovarsi tra loro più velocemente durante una reazione di rinaturazione, piuttosto che le sequenze ad alta complessità, poichè le sequenze a bassa complessità devono svolgere poche collisioni per cercare un partnerdi base con cui appaiarsi. Così, la velocità della reazione di rinaturazione è in funzione della complessità del DNA. In altre parole,la complessità del DNA può essere determinata misurando la costante di velocità di riassociazione di secondo-ordine. k2. Lenta, processo di. secondo-ordine a. velocità limitante, per trovare sequenze di. basi complementari.")
14
Cinetiche di riassociazione di DNA (per una singola specie di DNA)
Cot1/2 = 1 / k2 k2 = constante di velocità di secondo-ordine Co =concentrazione di DNA t1/2 = tempo di metà reazione log Cot A metà della reazione (cioè a t ½) il 50% è riassociato Questo punto è il Cot al t ½ cioè quelle condizioni che danno metà della totale rinaturazione % DNA riassociato 50 Questa figura mostra una reazione di rinaturazione di DNA (riassociazione) o “Curva Cot” di una singola specie di DNA , dove Co è la concentrazione di DNA e t è il tempo necessario ad ottenere il 50% della rinaturazione completa, come ad es. avviene nel DNA di E.coli. La reazione rappresentata nel grafico è un semi-logaritmo con “log Cot” sull’asse della x e % di DNA riassociato sull’asse della y.Questa reazione rappresenta una cinetica ideale di secondo-ordine. Cot è il prodotto di Co (concentrazione di DNA) e di t (tempo). Così, se la concentrazione di DNA è costante, l’asse della x è semplicemente il time course della reazione.La reazione procede come segue: al tempo 0 il DNA è denaturato in filamenti singoli e le condizioni sono aggiustate per promuovere l’apppaiamento delle basi per la rinaturazione del DNA; a t1/2 cioè a metà della reazione il 50% del DNA è riassociato. Questo punto è il Cot al tempo ½(tempo di mezza rinaturazione) ossia quelle condizioni di concentrazione e di tempo che danno metà della totale rinaturazione. In altre parole, la costante di velocità per un campione di DNA può essere determinata sperimentalmente misurando il Cot ½ della reazione. La costante di velocità allora fornisce prove sulla complessità del DNA comparando essa con le costanti di velocità di altri campioni di DNA di complessità nota. 100 Cot1/2 Ideale curva (curva Cot) di riassociazione di DNA di secondo-ordine
 il 50% è riassociato Questo punto è il Cot al t ½ cioè quelle condizioni che danno metà della totale rinaturazione. % DNA riassociato. 50. Questa figura mostra una reazione di rinaturazione di DNA (riassociazione) o Curva Cot di una singola specie di DNA , dove Co è la concentrazione di DNA e t è il tempo necessario ad ottenere il 50% della rinaturazione completa, come ad es. avviene nel DNA di E.coli. La reazione rappresentata nel grafico è un semi-logaritmo con log Cot sull’asse della x e % di DNA riassociato sull’asse della y.Questa reazione rappresenta una cinetica ideale di secondo-ordine. Cot è il prodotto di Co (concentrazione di DNA) e di t (tempo). Così, se la concentrazione di DNA è costante, l’asse della x è semplicemente il time course della reazione.La reazione procede come segue: al tempo 0 il DNA è denaturato in filamenti singoli e le condizioni sono aggiustate per promuovere l’apppaiamento delle basi per la rinaturazione del DNA; a t1/2 cioè a metà della reazione il 50% del DNA è riassociato. Questo punto è il Cot al tempo ½(tempo di mezza rinaturazione) ossia quelle condizioni di concentrazione e di tempo che danno metà della totale rinaturazione. In altre parole, la costante di velocità per un campione di DNA può essere determinata sperimentalmente misurando il Cot ½ della reazione. La costante di velocità allora fornisce prove sulla complessità del DNA comparando essa con le costanti di velocità di altri campioni di DNA di complessità nota Cot1/2. Ideale curva (curva Cot) di riassociazione di DNA di secondo-ordine.")
15
k2 >>>>>>>>>> k2
10,000 1 k2 >>>>>>>>>> k2 La complessità di sequenze influenza la velocità di riassociazione del DNA. Immaginiamo di avere 2 differenti sequenze di DNA in un genoma, una presente una volta per genoma aploide (destra) e l’altra presente volte (sinistra). Se queste sequenze sono mescolate insieme (che è in pratica ciò che succede nel DNA genomico totale che viene isolato per analisi), poi denaturate e lasciate riassociare, le sequenze ripetute dovrebbero associarsi più rapidamente perchè è molto più facile per esse trovare i filamenti complementari. Le sequenze ripetute si riassociano con un Cot1/2 molto basso e quindi con un k2 molto alto, in accordo con una rapida velocità di riassociazione.
 e l’altra presente volte (sinistra). Se queste sequenze sono mescolate insieme (che è in pratica ciò che succede nel DNA genomico totale che viene isolato per analisi), poi denaturate e lasciate riassociare, le sequenze ripetute dovrebbero associarsi più rapidamente perchè è molto più facile per esse trovare i filamenti complementari. Le sequenze ripetute si riassociano con un Cot1/2 molto basso e quindi con un k2 molto alto, in accordo con una rapida velocità di riassociazione.")
16
Complessità espressa come coppie di basi (bp)
100 101 102 103 104 105 106 107 108 109 1010 1 2 3 4 5 Cot1/2 Questa diapositiva mostra curve Cot da 5 differenti campioni di DNA che hanno complessità ampiamente differenti. Ogni DNA riassocia con una velocità che dipende dalla sua intrinseca complessità. Es il campione 1 che consiste di poliA-poliT è la sequenza più semplice possibile: essa è un doppio filamento di DNA costituito da omopolimeri di poliT appaiati a omopolimeri poliA. Per definizione ha una complessità di 1 perchè consiste di singole coppie di basi T-A ripetute. La velocità di riassociazione tra queste 2 catene complementari è altissima (ed il Cot ½ è bassissimo,10¯4) perchè l’incontro tra le 2 catene complementari è molto probabile visto che il DNA è formato solo da un’unica coppia di basi. Gli altri campioni (2-5) aumentano di complessità fino ad arrivare al campione 5 che è DNA umano a sequenza unica (o singola copia) in cui la velocità di rinaturazione sarà lenta per la scarsa probabilità di ogni catena di incontrarsi con quella complementare. 10-6 10-5 10-4 10-3 10-2 10-1 100 101 102 103 104 Cot C’è una relazione diretta tra Cot1/2 e la complessità 1 = poly(dT)-poly(dA) 2 = DNA satellite umano purificato 3 = DNA batteriofago T4 4 = DNA genomico di E. coli 5 = DNA umano a singola-copia purificato
 perchè l’incontro tra le 2 catene complementari è molto probabile visto che il DNA è formato solo da un’unica coppia di basi. Gli altri campioni (2-5) aumentano di complessità fino ad arrivare al campione 5 che è DNA umano a sequenza unica (o singola copia) in cui la velocità di rinaturazione sarà lenta per la scarsa probabilità di ogni catena di incontrarsi con quella complementare Cot. C’è una relazione. diretta tra Cot1/2. e la complessità. 1 = poly(dT)-poly(dA) 2 = DNA satellite umano purificato. 3 = DNA batteriofago T4. 4 = DNA genomico di E. coli. 5 = DNA umano a singola-copia purificato.")
17
Tipo di DNA % of Genoma Caratteristiche
Singola-copia (unica) Include la maggior parte dei geni 1 Disseminato attraverso il genoma tra e Ripetitivo (intersparso) entro i geni; include sequenze Alu 2 e VNTRs o mini (micro) satelliti Satellite (tandem) Altamente ripetuto, sequenze a bassa complessità di solito localizzate nei centromeri e telomeri 2 Le sequenze Alu sono circa 300 bp in lunghezza e sono ripetute circa 300,000 volte nel genoma. Esse possono trovarsi negli introni, adiacenti o entro i geni, o in regioni non tradotte. 1 Alcuni geni sono ripetuti da poche a migliaia di volte e così sono presenti nella frazione di DNA ripetitivo veloce intermedio Il genoma umano consiste di 3 popolazioni di DNA: le frazioni veloci e intermedie che costituiscono rispettivamente il 10% e 15% del genoma, e la frazione lenta che rappresenta il 75% del genoma. La maggior parte dei geni nel genoma umano sono nella frazione a singola copia. Le sequenze ripetute possono essere di 2 tipi: quelle che sono disseminate attraverso il genoma o quelle che sono DNA satelliti ripetuti disposte in tandem (uno dietro l’altro). Tra le sequenze ripetute disseminate ci sono le sequenze “Alu”, che sono circa 300 coppie di basi in lunghezza e che sono ripetute circa volte nel genoma. Esse si trovano adiacenti ai o entro i geni, e la loro presenza può qualche volta portare alla occasionale distruzione dei geni. Le sequenze ripetute disseminate includono anche VNTRs (numero variabile di ripetizioni in tandem), che sono costituite da corte sequenze ripetute di sole poche coppie di basi, ma di lunghezze variabili. Esse sono pure disseminate attraverso il genoma, e sono spesso utili come punto di riferimento per mappare i geni. 50 lento (singola-copia) 100 I I I I I I I I I
 Include la maggior parte dei geni 1. Disseminato attraverso il genoma tra e. Ripetitivo (intersparso) entro i geni; include sequenze Alu 2. e VNTRs o mini (micro) satelliti. Satellite (tandem) Altamente ripetuto, sequenze a bassa complessità. di solito localizzate nei centromeri e telomeri. 2 Le sequenze Alu sono. circa 300 bp in lunghezza. e sono ripetute circa. 300,000 volte nel. genoma. Esse possono. trovarsi negli introni, adiacenti o. entro i geni, o in regioni. non tradotte. 1 Alcuni geni sono ripetuti da poche a migliaia di volte e così sono presenti nella. frazione di DNA ripetitivo. veloce. intermedio. Il genoma umano consiste di 3 popolazioni di DNA: le frazioni veloci e intermedie che costituiscono rispettivamente il 10% e 15% del genoma, e la frazione lenta che rappresenta il 75% del genoma. La maggior parte dei geni nel genoma umano sono nella frazione a singola copia. Le sequenze ripetute possono essere di 2 tipi: quelle che sono disseminate attraverso il genoma o quelle che sono DNA satelliti ripetuti disposte in tandem (uno dietro l’altro). Tra le sequenze ripetute disseminate ci sono le sequenze Alu , che sono circa 300 coppie di basi in lunghezza e che sono ripetute circa volte nel genoma. Esse si trovano adiacenti ai o entro i geni, e la loro presenza può qualche volta portare alla occasionale distruzione dei geni. Le sequenze ripetute disseminate includono anche VNTRs (numero variabile di ripetizioni in tandem), che sono costituite da corte sequenze ripetute di sole poche coppie di basi, ma di lunghezze variabili. Esse sono pure disseminate attraverso il genoma, e sono spesso utili come punto di riferimento per mappare i geni. 50. lento (singola-copia) 100. I I I I I I I I I.")
18
Cinetiche di riassociazione di DNA da una miscela di specie di DNA
Cot1/2 = 1 / k k2= constante di velocità di secondo-ordine Co = concentrazione DNA t1/2 = tempo di metà reazione Frazioni cinetiche : veloce intermedia lenta veloce (ripetute) intermedia (ripetute) Cot1/2 % DNA riassociato 50 Questa diapositiva mostra una curva Cot del DNA genomico umano. Questo DNA mostra cinetiche di riassociazione complesse perchè è una miscela di 3 differenti specie o popolazioni di DNA: frazione di riassociazione veloce, intermedia e lenta. Le frazioni veloce e intermedia sono composte di sequenze ripetute nel genoma, e la frazione lenta è composta da sequenze di DNA a singola copia. Le sequenze di DNA a singola copia sono quelle che sono presenti in singola per genoma aploide. La prossima diapositiva mostra il concetto di come la complessità di sequenze influenza la velocità di riassociazione del DNA. Cot1/2 lenta (singola-copia) Cot1/2 100 I I I I I I I I I log Cot DNA genomico umano
 intermedia. (ripetute) Cot1/2. % DNA riassociato. 50. Questa diapositiva mostra una curva Cot del DNA genomico umano. Questo DNA mostra cinetiche di riassociazione complesse perchè è una miscela di 3 differenti specie o popolazioni di DNA: frazione di riassociazione veloce, intermedia e lenta. Le frazioni veloce e intermedia sono composte di sequenze ripetute nel genoma, e la frazione lenta è composta da sequenze di DNA a singola copia. Le sequenze di DNA a singola copia sono quelle che sono presenti in singola per genoma aploide. La prossima diapositiva mostra il concetto di come la complessità di sequenze influenza la velocità di riassociazione del DNA. Cot1/2. lenta (singola-copia) Cot1/ I I I I I I I I I. log Cot. DNA genomico umano.")
19
Classi di DNA ripetitivo
Ripetizioni Intersparse (disperse) (e.g., Alu sequences) GCTGAGG GCTGAGG GCTGAGG Ripetizioni Tandem (e.g., microsatelliti) TTAGGGTTAGGGTTAGGGTTAGGG Le ripetizioni disseminate (disperse) sono sequenze che sono ripetute molte volte e sparse attraverso il genoma. In contrasto, le ripetizioni a tandem sono sequenze che sono ripetute molte volte adiacenti le une alle altre. Di solito si trovano nei centromeri e nei telomeri dei cromosomi.
 (e.g., Alu sequences) GCTGAGG. GCTGAGG. GCTGAGG. Ripetizioni Tandem (e.g., microsatelliti) TTAGGGTTAGGGTTAGGGTTAGGG. Le ripetizioni disseminate (disperse) sono sequenze che sono ripetute molte volte e sparse attraverso il genoma. In contrasto, le ripetizioni a tandem sono sequenze che sono ripetute molte volte adiacenti le une alle altre. Di solito si trovano nei centromeri e nei telomeri dei cromosomi.")
20
Proprietà del genoma umano
Nucleare il genoma umano aploide ha ~3 X 109 bp di DNA DNA a singola-copia comprende ~75% del genoma umano il genoma umano contiene ~30,000 a 40,000 geni la maggior parte dei geni sono a singola-copia nel genoma aploide i geni sono composti da 1 a >75 esoni i geni variano in lunghezza da <100 a >2,300,000 bp le sequenze Alu sono presenti attraverso il genoma Mitocondriale genoma circolare di ~17,000 bp contiene <40 geni

21
b). Struttura del Gene promoter region
esoni (regioni nel box riempite e nonriempite) +1 introni (tra gli esoni) regioni tradotte Questa diapositiva mostra la struttura di un tipico gene umano e il suo corrispondente RNA messaggero (mRNA). La maggior parte dei geni nel genoma umano sono chiamati “geni interrotti” perchè sono composti da esoni separati da introni. Gli esoni sono regioni dei geni che codificano informazioni che finiscono in mRNA. La regione tradotta di un gene (freccia) inizia al nucleotide +1 all’estremità 5’ del primo esone e include tutti gli esoni e gli introni (l’inizio della trascrizione è regolato dalla regione del promoterdel gene, che è a monte del sito +1).Il processamento dell’RNA rimuove poi le sequenze introniche, unendo insieme le sequenze esoniche per produrre l’RNA maturo. La regione tradotta dell’mRNA (la regione che codifica la proteina) è indicata in blu. Notare che ci sono regioni non tradotte alle estremità 5’ e 3’ dell’mRNA che sono codificate da sequenze esoniche ma non sono direttamente tradotte. mRNA structure 5’ 3’ regione tradotta
 +1. introni (tra gli esoni) regioni tradotte. Questa diapositiva mostra la struttura di un tipico gene umano e il suo corrispondente RNA messaggero (mRNA). La maggior parte dei geni nel genoma umano sono chiamati geni interrotti perchè sono composti da esoni separati da introni. Gli esoni sono regioni dei geni che codificano informazioni che finiscono in mRNA. La regione tradotta di un gene (freccia) inizia al nucleotide +1 all’estremità 5’ del primo esone e include tutti gli esoni e gli introni (l’inizio della trascrizione è regolato dalla regione del promoterdel gene, che è a monte del sito +1).Il processamento dell’RNA rimuove poi le sequenze introniche, unendo insieme le sequenze esoniche per produrre l’RNA maturo. La regione tradotta dell’mRNA (la regione che codifica la proteina) è indicata in blu. Notare che ci sono regioni non tradotte alle estremità 5’ e 3’ dell’mRNA che sono codificate da sequenze esoniche ma non sono direttamente tradotte. mRNA structure. 5’ 3’ regione tradotta.")
22
(esone-introne-esone)n struttura di diversi geni
istone totale = 400 bp; 1 solo esone = 400 bp b-globina totale = 1,660 bp; 3 esoni = 990 bp; 2 introni Questa diapositiva mostra esempi di una grande varietà di strutture di geni che si trovano nel genoma umano. Alcuni (molto pochi) geni non hanno introni. Un esempio ci è fornito dai geni degli istoni, che codificano piccole proteine leganti il DNA, l’istone H1, H2A, H2B, H3, H4. In figura è mostrato il gene istone che ha solo 400 coppie di basi (bp) in lunghezza ed è composto da un solo esone. Il gene della b-globina ha 3 esoni e 2 introni. Il gene ipoxantina-guanina phosphoribosil transferasi (HGPRT or HPRT) ha 9 esoni ed è 100 volte più grande del gene istone, ancora ha un mRNA che è 3 volte più grande dell’mRNA dell’istone (lunghezza totale esone è bp).Ciò è dovuto al fatto che gli introni possono essere molto lunghi, mentre gli esoni sono di solito relativamente corti. Un esempio estremo di ciò è il gene del fattore VIII che ha numerosi esoni (Box blu e linee verticali blu). HGPRT (HPRT) ipoxantina-guanina totale = 42,830 bp; 9 esoni = 1263 bp factor VIII totale = ~186,000 bp; molti esoni = ~9,000 bp
 geni non hanno introni. Un esempio ci è fornito dai geni degli istoni, che codificano piccole proteine leganti il DNA, l’istone H1, H2A, H2B, H3, H4. In figura è mostrato il gene istone che ha solo 400 coppie di basi (bp) in lunghezza ed è composto da un solo esone. Il gene della b-globina ha 3 esoni e 2 introni. Il gene ipoxantina-guanina phosphoribosil transferasi (HGPRT or HPRT) ha 9 esoni ed è 100 volte più grande del gene istone, ancora ha un mRNA che è 3 volte più grande dell’mRNA dell’istone (lunghezza totale esone è bp).Ciò è dovuto al fatto che gli introni possono essere molto lunghi, mentre gli esoni sono di solito relativamente corti. Un esempio estremo di ciò è il gene del fattore VIII che ha numerosi esoni (Box blu e linee verticali blu). HGPRT (HPRT) ipoxantina-guanina. totale = 42,830 bp; 9 esoni = 1263 bp. factor VIII. totale = ~186,000 bp; molti esoni = ~9,000 bp.")
23
Familial hypercholesterolemia autosomal dominant
LDL receptor deficiency La più comune malattia autosomica dominante (~1 su 500) come l’ipercolesterolemia familiare (FH) è causata da una mutazione del recettore LDL (lipoproteina a bassa densità) del gene. Le LDL del plasma, che legano il colesterolo circolante, sono liberate dal siero mediante il legame al recettore LDL situato sulle cellule epatiche e così il colesterolo è internalizzato. Livelli normali di colesterolo nel plasma sono al di sotto di 200 mg/dl. Individui che hanno un gene difettivo del recettore LDL (eterozigoti) hanno approssimativamente doppia quantità di colesterolo, e quelli che hanno 2 geni difettivi (omozigoti) hanno circa 4 volte maggiore questa quantità. Individui eterozigoti sono predisposti a malattie cardiovascolari, con gli uomini che hanno un rischio del 50% di infarto del miocardio. Ci sono alcuni modi per cui il gene del recettore LDL è mutato rendendolo inattivo. Un probabile meccanismo coinvolge le sequenze Alu.
 come l’ipercolesterolemia familiare (FH) è causata da una mutazione del recettore LDL (lipoproteina a bassa densità) del gene. Le LDL del plasma, che legano il colesterolo circolante, sono liberate dal siero mediante il legame al recettore LDL situato sulle cellule epatiche e così il colesterolo è internalizzato. Livelli normali di colesterolo nel plasma sono al di sotto di 200 mg/dl. Individui che hanno un gene difettivo del recettore LDL (eterozigoti) hanno approssimativamente doppia quantità di colesterolo, e quelli che hanno 2 geni difettivi (omozigoti) hanno circa 4 volte maggiore questa quantità. Individui eterozigoti sono predisposti a malattie cardiovascolari, con gli uomini che hanno un rischio del 50% di infarto del miocardio. Ci sono alcuni modi per cui il gene del recettore LDL è mutato rendendolo inattivo. Un probabile meccanismo coinvolge le sequenze Alu.")
24
X Gene del recettore LDL Ripetizioni Alu presenti entro gli introni 4
5 6 Ripetizioni Alu in esoni crossing over ineguale 4 5 6 Alu Alu X In questa diapositiva è visibile la struttura del gene del recettore LDL (che ha 18 esoni). Sei sequenze Alu sono presenti in 3 degli introni e 2 degli esoni. A causa della stretta vicinanza delle 2 ripetizioni Alu localizzate entro gli introni 4 e 5, avviene un ineguale crossing over durante un evento meiotico che si manifesta alcune generazioni dopo. Il crossing over richiede sequenze omologhe con cui si ha appaiamento di basi durante la meiosi. Le sequenze omologhe sono fornite dalle ripetizioni Alu, che causano un cattivo allineamento fuori registro e susseguente crossing over che risulta in una delezione dell’esone 5 da uno dei due prodotti del crossing over. Questo cromosoma è ereditato ed è causa di FH. Così, mentre le sequenze Alu non hanno funziona nota nel nostro genoma, ci sono molte di queste sequenze disperse attraverso il genoma,dentro e attorno i geni, e possono essere completamente distrutte. Alu Alu 4 5 6 1 prodotto ha un esone 5 deleto (l’altro prodotto non è mostrato) Alu 4 6
. Sei sequenze Alu sono presenti in 3 degli introni e 2 degli esoni. A causa della stretta vicinanza delle 2 ripetizioni Alu localizzate entro gli introni 4 e 5, avviene un ineguale crossing over durante un evento meiotico che si manifesta alcune generazioni dopo. Il crossing over richiede sequenze omologhe con cui si ha appaiamento di basi durante la meiosi. Le sequenze omologhe sono fornite dalle ripetizioni Alu, che causano un cattivo allineamento fuori registro e susseguente crossing over che risulta in una delezione dell’esone 5 da uno dei due prodotti del crossing over. Questo cromosoma è ereditato ed è causa di FH. Così, mentre le sequenze Alu non hanno funziona nota nel nostro genoma, ci sono molte di queste sequenze disperse attraverso il genoma,dentro e attorno i geni, e possono essere completamente distrutte. Alu. Alu prodotto ha un esone 5 deleto. (l’altro prodotto non è mostrato) Alu")
26
45% ripetizioni intersperse
Struttura genoma umano Si divide in: 25% GENICO Sequenza di nucleotidi simile a un gene ma non in grado di produrre proteine funzionali 1,5% quello che esprime 23,5% introni e pseudogeni 45% ripetizioni intersperse 50% sequenze ripetute 5% Segmenti Duplicati 75% INTRAGENICO Il mappaggio del genoma ci dice che gli introni costituiscono circa il 20% mentre circa il 60% di DNA è fatto di sequenze ripetute. Oggi le sequenze genomiche sono annotate nei data base e svelano non solo le sequenze dei geni codificanti proteine ma anche sequenze di elementi regolatori la cui identificazione è molto difficile perché la maggior parte degli elementi regolatori sono piccole sequenze di DNA lunghe 10 paia di basi. 25% DNA spaziatore

27
• sequenze ripetute derivate da trasposoni (intersperse)
Nel genoma umano le sequenze ripetute costituiscono almeno il 50% del totale e sono suddivise in 5 classi: • sequenze ripetute derivate da trasposoni (intersperse) • copie inattive di geni • ripetizioni di sequenze semplici (minisatelliti e microsatelliti): (A)n, (CA)n, (CGG)n • duplicazioni segmentali • sequenze ripetute in tandem (centromeri, telomeri, cluster ribosomali) Il 45% delle ripetizioni intersperse è dato da trasposoni e retrotrasposoni. I trasposoni sono elementi ripetuti in grado di muoversi nel genoma, costituiti tra le 80 e le paia di basi Le differenze tra queste due classi risiedono nella differente modalità di inserimento della molecola di DNA: il trasposone copia gli elementi direttamente in DNA,il retrotrasposone utilizza come intermedio una molecola di RNA convertendola in DNA (questo processo, cioè il passaggio da una molecola di RNA ad una di DNA, nel 1975 non sembrava possibile). I RETROTRASPOSONI si dividono in •NON VIRALI LINE S(Long Interdispersed Elements (6-7 kb) SINES ( Short Interdispersed Elements ( bp) ES. Alu •VIRALI RIPETIZIONI LTR (Long Terminal Repeats) Le ripetizioni LTR dei retroasposoni virali sono sequenze ripetute che permettono lo spostamento della molecola di DNA mobile, e rappresentano le porzioni terminali sia destra che sinistra della molecola.
 • copie inattive di geni. • ripetizioni di sequenze semplici (minisatelliti e microsatelliti): (A)n, (CA)n, (CGG)n. • duplicazioni segmentali. • sequenze ripetute in tandem (centromeri, telomeri, cluster ribosomali) Il 45% delle ripetizioni intersperse è dato da trasposoni e retrotrasposoni. I trasposoni sono elementi ripetuti in grado di muoversi nel genoma, costituiti tra le 80 e le paia di basi Le differenze tra queste due classi risiedono nella differente modalità di inserimento della molecola di DNA: il trasposone copia gli elementi direttamente in DNA,il retrotrasposone utilizza come intermedio una molecola di RNA convertendola in DNA (questo processo, cioè il passaggio da una molecola di RNA ad una di DNA, nel 1975 non sembrava possibile). I RETROTRASPOSONI si dividono in. •NON VIRALI. LINE S(Long Interdispersed Elements (6-7 kb) SINES ( Short Interdispersed Elements ( bp) ES. Alu. •VIRALI. RIPETIZIONI LTR (Long Terminal Repeats) Le ripetizioni LTR dei retroasposoni virali sono sequenze ripetute che permettono lo spostamento della molecola di DNA mobile, e rappresentano le porzioni terminali sia destra che sinistra della molecola.")
Presentazioni simili












 + soluto In genere solvente liquido (es.acqua) E soluto solido, liquido, aeriforme.>")




1 Soluzioni e sospensioni.>")





