Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
Sistemi informativi statistici In sintesi: SIS I SIS sono sistemi multi-fonte e multi-utente pertanto: necessitano di metadati globali i progettisti dei SIS devono preoccuparsi di rendere disponibili non solo i dati ma anche i metadati globali sviluppando sistemi specializzati nella definizione e gestione di tali tipi di metadati che non sono di facile implementazione poiché la costruzione di un metadato globale richiede un delicato e complesso lavoro di standardizzazione ed integrazione.

2
Sistemi informativi statistici Esempio di una possibile strategia per lo sviluppo di sistemi di gestione di metadati Sviluppare due sistemi, nell’ottica di un’integrazione successiva, per: 1.gestire tutte le classi di metadati che descrivono l’indagine come processo 2.gestire le classi di metadati che riguardano i contenuti informativi e delle altre fonti e fornire gli strumenti per confrontare ed integrare le diverse definizioni dei contenuti informativi

3
Sistemi informativi statistici SIS Un esempio di SIS: il Sistema Informativo Universitario (SIU) Obiettivo: costituzione di un Sistema Informativo Universitario orientato alla valutazione. Piano operativo: 1.Individuazione del fabbisogno informativo 2.Reperimento dei dati non disponibili 3.Sviluppo degli indicatori derivabili Scelte di fondo: 1.Rendere il SIU utile ai diversi livelli decisionali (Istat, MIUR, CRUI, CNVSU, Atenei, Regioni, Province, Comuni) 2.Mettere a disposizione sia i dati elementari che un set minimo di indicatori descrittivi
 2.Mettere a disposizione sia i dati elementari che un set minimo di indicatori descrittivi.")
4
Sistemi informativi statistici Il database SIU - contenuti: Studenti Personale Finanze Ricerca Edilizia Contesto Fonti: Atenei CINECA indagini sugli sbocchi occupazionali dei laureati spese sostenute dalle famiglie per la formazione Miur (FFO, diritto allo studio) Istat (statistiche demografiche, forze lavoro, bilanci universitari) Il sistema di supporto all’attività di ricerca, accesso ed elaborazione dell’informazione di interesse offre diverse funzioni di manipolazione dei dati, che consentono in tempo reale l’estrazione della propria informazione di interesse, e l’accesso alle funzionalità offerte dai sistemi OLAP/Datawarehousing
 Istat (statistiche demografiche, forze lavoro, bilanci universitari) Il sistema di supporto all’attività di ricerca, accesso ed elaborazione dell’informazione di interesse offre diverse funzioni di manipolazione dei dati, che consentono in tempo reale l’estrazione della propria informazione di interesse, e l’accesso alle funzionalità offerte dai sistemi OLAP/Datawarehousing")
5
Sistemi informativi statistici Osservazioni SIS Nella progettazione del SIU si è previsto fin dalla fase iniziale di tener conto degli indicatori che avrebbero potuto essere utili per il monitoraggio del settore. Tale scelta ha comportato che i progettisti non perdessero mai di vista l’integrazione delle diverse fonti enfatizzando la caratteristica del SIS come sistema per il raccordo delle conoscenze su un fenomeno, piuttosto che come un bacino in cui convogliare informazioni diverse, seppure riconducibili ad uno stesso fenomeno. Il SIU appare come un sistema concepito come base di conoscenza ed effettivamente modellato sulle esigenze dell’utenza. SIS L’esperienza di realizzazione del SIU ha consentito di rendere esplicita la distinzione dei due momenti che caratterizzano la progettazione di un SIS quella in cui si delinea un sistema coerente ed integrato di fonti e quella in cui si progettano i sistemi di supporto alla gestione ed all’uso dei dati che concretamente lo realizzano.

6
Data warehouse

7
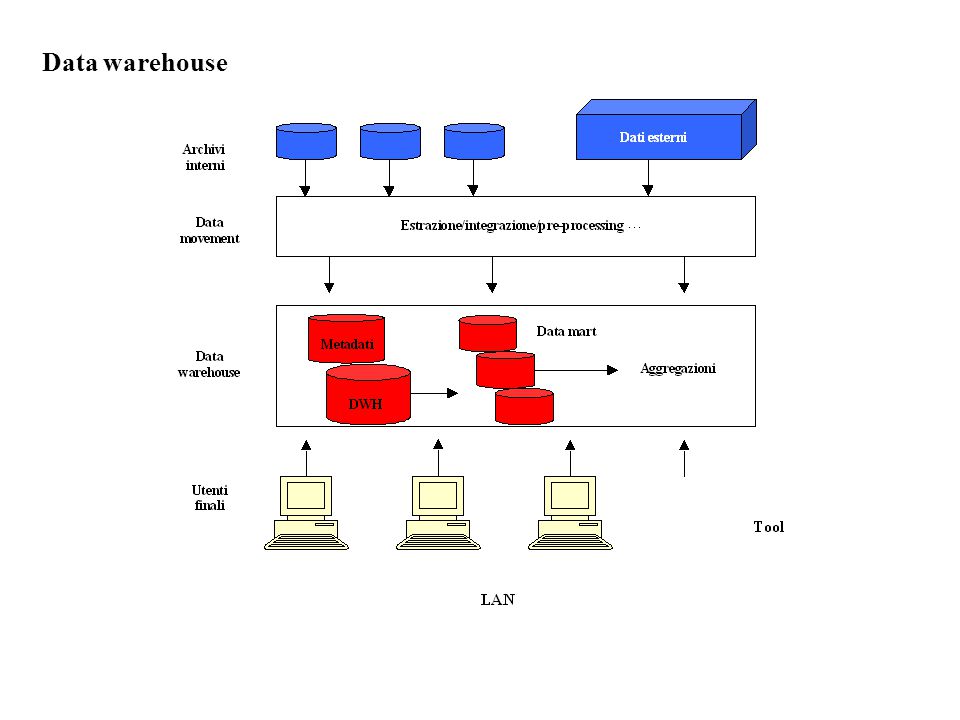
Un singolo integrato database che fornisce l’infrastruttura necessaria per le applicazioni informative dell’azienda. Una piattaforma sulla quale vengono archiviati e gestiti i dati provenienti dalle diverse aree dell’organizzazione. Tali dati sono aggiornati, integrati e consolidati dai sistemi di carattere operativo per supportare tutte le applicazioni di supporto alle decisioni. Un insieme di dati subject oriented, integrato, time variant, non volatile costruito per supportare il processo decisionale.Un insieme di dati subject oriented, integrato, time variant, non volatile costruito per supportare il processo decisionale. Definizioni Data warehouse

8
Secondo Inmon la raccolta di dati è: subject oriented: perché il DWH è orientato a temi specifici dell’azienda (clienti, prodotti, ecc.) piuttosto che alle applicazioni o funzioni (quali ad esempio in un contesto bancario alle applicazioni transazionali). Nel DWH i dati vengono archiviati in modo che possano essere facilmente letti o elaborati dagli utenti cioè in modo da favorire la produzione di informazioni; integrata: requisito fondamentale del DWH in quanto in esso confluiscono dati provenienti da più fonti; time-variant: i dati rappresentano delle istantanee scattate in precisi istanti temporali che colgono, quindi, la situazione relativa ad un determinato fenomeno in un determinato intervallo temporale piuttosto esteso; non volatile: il dato viene caricato ed acceduto fuori linea cioè non può essere modificato dall’utente (l’accesso è in sola lettura). Data warehouse
. Data warehouse.")
9
1.I dati provenienti da fonti diverse 2.Il data movement o data warehousing 3.Il data warehouse ed il data mart 4.I metadati 5.L’utente finale Principali componenti Data warehouse

11
Sono i dati che provengono da sistemi transazionali (sistemi gestionali che hanno il compito di automatizzare le operazioni di routine o transazionali), da indagini, da banche dati esterne. 1.I dati provenienti da fonti diverse Data warehouse V Tale componente è responsabile dell’estrazione dei dati da tutte le fonti individuate, dell’integrazione tra le varie fonti, del pre-processing dei dati, del controllo della consistenza dei dati, della conversione della struttura dei dati e dell’aggiornamento dei dizionari dei dati. 2.Il data movement o data warehousing

12
Il data warehouse è sempre fisicamente separato dalle sorgenti informative ed anche le procedure di analisi non avvengono quasi mai su di esso ma su speciali collezioni chiamate data mart o basi di dati multidimensionali. I data mart rappresentano data warehouse tematici di più piccole dimensioni. Se ne possono estrarre tanti quante sono le finalità che si vogliono perseguire con la successiva analisi. Sono rapidamente accessibili e convertibili in strutture statistiche (matrici dei dati). Come esempio di data mart si pensi ad uno orientato al settore marketing in cui i dati vengono filtrati dai sistemi transazionali per supportare l’analisi della clientela. 3.Il data warehouse ed il data mart Data warehouse
. Come esempio di data mart si pensi ad uno orientato al settore marketing in cui i dati vengono filtrati dai sistemi transazionali per supportare l’analisi della clientela. 3.Il data warehouse ed il data mart Data warehouse.")
13
Gli archivi di metadati in gergo DWH vengono chiamati information catalog. Mentre come tipologia si individuano: Metadati tecnici. Forniscono informazioni sull’ubicazione dei sistemi sorgente, la frequenza refresh/update, la sicurezza, i tracciati record, ecc. (usati da analisti e programmatori per gestire e realizzare il data warehouse) Metadati di business. Specificano il disegno campionario, i questionari, il software, la definizione delle variabili, ecc. (usati per supporto alle analisi, per valutare la qualità dell’indagine, per la diffusione del dato) Metadati amministrativi. Sono relativi al budget, ai costi, alla programmazione, ecc. (usati per pianificare eventuali successive indagini) 4.I metadati (data about the data) Data warehouse
 Metadati di business. Specificano il disegno campionario, i questionari, il software, la definizione delle variabili, ecc. (usati per supporto alle analisi, per valutare la qualità dell’indagine, per la diffusione del dato) Metadati amministrativi. Sono relativi al budget, ai costi, alla programmazione, ecc. (usati per pianificare eventuali successive indagini) 4.I metadati (data about the data) Data warehouse.")
14
I dati contenuti nel data warehouse vengono presentati all’utente finale che dispone di un insieme di strumenti che consentono di effettuare elaborazioni per produrre informazioni appropriate. Tale attività è definita Knowdlege Discovery in Databases (KDD) e racchiude tutti i metodi il cui scopo sia la ricerca di relazioni e regolarità nei dati osservati. Più in generale il KDD rappresenta l’intero processo di estrazione della conoscenza in un database, dall’individuazione degli obiettivi dell’analisi all’applicazione delle regole decisionali individuate. 5.L’utente finale Data warehouse
 e racchiude tutti i metodi il cui scopo sia la ricerca di relazioni e regolarità nei dati osservati. Più in generale il KDD rappresenta l’intero processo di estrazione della conoscenza in un database, dall’individuazione degli obiettivi dell’analisi all’applicazione delle regole decisionali individuate. 5.L’utente finale Data warehouse.")
15
Il processo di scoperta della conoscenza - 1 1.Definizione e comprensione del dominio applicativo e definizione degli obiettivi da realizzare 2.Creazione di un target data set selezionando un sottoinsieme di variabili e di dati o campionando i dati 3.Procedere ad operazioni di data cleanising e pre-processing (valori fuori range, dati mancanti, outliers, selezione delle informazioni necessarie per generare il modello, definizione della dimensione storica dai dati da trattare e definizione delle modalità di aggiornamento) 4.Riduzione del numero delle variabili attraverso l’utilizzo di metodi di trasformazione 5.Scelta del ruolo dei sistemi di data mining per l’analisi (per classificazione, regressione, clusterizzazione, ecc.) 6.Scelta del o degli algoritmi di data mining per l’analisi Data warehouse
 4.Riduzione del numero delle variabili attraverso l’utilizzo di metodi di trasformazione 5.Scelta del ruolo dei sistemi di data mining per l’analisi (per classificazione, regressione, clusterizzazione, ecc.) 6.Scelta del o degli algoritmi di data mining per l’analisi Data warehouse")
16
Il processo di scoperta della conoscenza – 2 7.Applicazione degli algoritmi di data mining 8.Interpretazione dei modelli identificati, possibile retroazione per ulteriori interazioni 9.Consolidamento della conoscenza scoperta integrando la conoscenza, valutando le performance del sistema, producendo della documentazione per gli utenti finali o terze parti interessate N.B.: Il processo non si conclude in un’unica interazione. È necessario prevedere il raffinamento successivo dei risultati ottenuti per pervenire alla versione ottimale del modello Data warehouse

17
QUERY E REPORTING Strumenti DATA RETRIEVAL OLAP DATA MINING Data warehouse

18
Query e reporting Strumenti veloci e facili da usare che permettono di esplorare i dati aziendali a vari livelli, recuperando le specifiche informazioni richieste (strumenti di query), e presentandole in modo chiaro e comprensibile (strumenti di reporting). Data warehouse Data retrieval Strumento che consente l’estrazione dei dati secondo criteri definiti a priori. Ad esempio l’estrazione dei dati anagrafici di tutti i lavoratori che lavorano in un determinato reparto dell’azienda e che hanno subito degli infortuni.

19
OLAP (On-line OnAnalytical Processing) Strumento utilizzato per verificare se certe relazioni sono vere. L’utente formula delle ipotesi sulle possibili relazioni esistenti tra le variabili e cerca delle conferme osservando i dati, presentandoli secondo opportune rappresentazioni grafiche. L’estrazione è effettuata in modo puramente informatico, senza avvalersi dei strumenti di modellazione e di sintesi forniti dalla metodologia statistica. Data warehouse

20
Data mining (DM) Processo di selezione, esplorazione e modellazione di grandi masse di dati, mirato alla scoperta di regolarità o relazioni non note a priori, in modo automatico o semiautomatico. E’ un approccio multidisciplinare che riunisce un insieme di tecniche quali la statistica, la visualizzazione e i sistemi basati sulla conoscenza ed i sistemi ad autoapprendimento, finalizzate al miglioramento dei processi conoscitivi ed a ridurre l’incertezza legata all’assunzione di decisioni. Data warehouse

21
Le principali e più innovative tecniche di DM Visualizzazione Reti neurali Algoritmi genetici Fuzzy logic Alberi decisionali e rule induction Data mining

22
Tipologie di problemi ai quali il DM fornisce una risposta Data mining ProblemiDefinizioni ClassificazioneDefinizione delle caratteristiche del data set ClusteringIdentificazione delle affinità che definiscono i gruppi in un data set che mostrano comportamenti simili SequencingIdentificazione delle correlazioni tra comportamenti all’interno di un periodo definito AssociazioneIdentificazione delle correlazioni tra comportamenti che ricorrono nello stesso periodo PrevisioneIdentificazione di trend basata su dati storici

23
Data mining Tipologie di domande alle quali il DM fornisce una risposta DomandeTipo di Problema Tecnica adottabile Quali sono i tre principali motivi che hanno indotto il mio cliente a passare alla concorrenza? ClassificazioneReti neurali Alberi decisionali Quali sono le fasce di clienti a cui posso offrire nuovi prodotti/servizi? ClusteringReti neurali Alberi decisionali Quali sono le probabilità che un cliente che ha aperto un c/c acquisterà anche il prodotto X in breve tempo? SequencingTecniche statistiche Rule induction Quali sono le probabilità che un cliente acquisti due prodotti completamente differenti? AssociazioneTecniche statistiche Rule induction Quale sarà il prezzo del titolo tra un giorno/mese? PrevisioneReti neurali Tecniche statistiche

24
Ma non se ne occupava la statistica? Data mining J. Kettenring (ex- presidente dell’ASA) definisce la statistica come “la scienza di apprendere dai dati” Tecniche statistiche orientate alla scoperta di strutture di relazione e di modelli Analisi esplorativa Analisi esplorativa multivariata Analisi delle componenti principali Analisi delle corrispondenze Analisi dei cluster Ecc.
 definisce la statistica come la scienza di apprendere dai dati Tecniche statistiche orientate alla scoperta di strutture di relazione e di modelli Analisi esplorativa Analisi esplorativa multivariata Analisi delle componenti principali Analisi delle corrispondenze Analisi dei cluster Ecc..")
25
Cosa c’e’ di nuovo nel Data mining? La possibilità di gestire enormi quantità di dati, che rendono obsoleta la definizione classica di grandi campioni (miliardi di record e terabytes di dati non sono inusuali) Le recenti tecniche che provengono dal mondo dell’ingegneria informatica (reti neurali, alberi di decisione, regole di inclusione) Interessi commerciali nel valorizzare le informazioni esistenti al fine di proporre soluzioni “individuali” per una determinata categoria di clienti Disponibilità di nuovi pacchetti, di facile uso, diretti sia a coloro i quali devono assumere le decisioni che agli analisti (ma molto più costosi!) Data mining
 Le recenti tecniche che provengono dal mondo dell’ingegneria informatica (reti neurali, alberi di decisione, regole di inclusione) Interessi commerciali nel valorizzare le informazioni esistenti al fine di proporre soluzioni individuali per una determinata categoria di clienti Disponibilità di nuovi pacchetti, di facile uso, diretti sia a coloro i quali devono assumere le decisioni che agli analisti (ma molto più costosi!) Data mining.")
26
Il text mining Data mining Potenti tecniche sono disponibili per classificare, analizzare, e raggruppare informazioni o documenti creati con pacchetti di video scrittura Esempi Classificazione delle notizie dei giornali Raggruppare e-mail secondo argomenti prestabiliti Archiviare in automatico i documenti in base al loro contenuto Ecc.

27
Conclusioni Data mining Il Data mining è una disciplina in grande crescita che si è sviluppata al di fuori della statistica nel mondo dei DBMS, principalmente per motivi commerciali. Oggi il DM si può considerare come una branca della statistica esplorativa con l’obiettivo di individuare inattesi e utili modelli e regolarità nei dati mediante l’uso di algoritmi classici e nuovi.

28
AVVERTENZE ALL’USO Data mining L’espressione inattesi non deve essere fuorviante: un ricercatore ha una maggiore possibilità di scoprire qualcosa di interessante se ha familiarità con i dati. L’utilità delle regolarità individuate nella struttura dei dati va verificata. Le associazioni sono solo correlazioni e non implicano relazioni di causa-effetto. Non va infine dimenticato che nell’applicazione di questi algoritmi è necessario effettuare valutazioni dell’incertezza e del rischio e pertanto non si può prescindere dall’uso di test per la verifica della validità dei risultati ottenuti (suddividere la base di dati in sotto campioni e verificare se si ottengono gli stessi risultati).
..")
29
Business Intelligence business intelligence In ambito aziendale l’insieme delle applicazioni, dei programmi e delle tecnologie usate per raccogliere, immagazzinare, analizzare e garantire accesso ai dati finalizzate a supportare gli utenti a prendere decisioni di business più efficaci viene indicato con il termine business intelligence (BI). Le applicazioni di BI includono, quindi, le attività di: supporto alle decisioni, interrogazione e reporting, OLAP, analisi statistica e DM.

Presentazioni simili





>")













>")