Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
L’errore sperimentale e la sua valutazione nelle determinazioni analitiche
Ogni misura presenta una qualche incertezza, chiamata errore sperimentale Media aritmetica: è rappresentata dal numero ottenuto dividendo la somma di una serie di valori numerici per il numero totale delle misure effettuate x = i=1 N xi Mediana: è il valore centrale di un set di dati che sono stati ordinati in ordine numerico Media geometrica: M(g)= N (x1 x2 x3….. xi) . La media geometrica si usa al posto di quella aritmetica nei casi in cui le quantità variano esponenzialmente (emissioni radioattive, conc. plasmatiche metaboliti)
= N. (x1 x2 x3….. xi) . La media geometrica si usa al posto di quella aritmetica nei casi in cui le quantità variano esponenzialmente (emissioni radioattive, conc. plasmatiche metaboliti)")
2
Errore sistematico o errore determinato: è un errore ricorrente (riproducibile) che può essere rivelato e corretto (strumentazione non tarata, errori di metodo, errore personali) ACCURATEZZA: indica la vicinanza della misura al valore vero (accettato) Errore casuale: deriva dall’effetto prodotto da una serie di variabili incontrollate (e talvolta incontrollabili: variazioni temperatura e tensione elettrica, vibrazioni) PRECISIONE: descrive la riproducibilità delle misurazioni Errore grossolano: si presenta occasionalmente, è spesso elevato e fa sì che un singolo dato si discosti da tutti gli altri dati di una serie di misure replicate
 PRECISIONE: descrive la riproducibilità delle misurazioni. Errore grossolano: si presenta occasionalmente, è spesso elevato e fa sì che un singolo dato si discosti da tutti gli altri dati di una serie di misure replicate.")
3
Errore assoluto = valore osservato – valore vero
Errore sistematico L’errore sistematico viene rivelato utilizzando opportuni std. di riferimento (analita a concentrazione nota) e calcolando l’accuratezza L’accuratezza di una misura è il grado di accordo tra essa e il valore vero e viene espressa dall’errore (assoluto o relativo) Errore assoluto = valore osservato – valore vero valore osservato – valore vero Errore relativo = x100 valore vero
 e calcolando l’accuratezza. L’accuratezza di una misura è il grado di accordo tra essa e il valore vero e viene espressa dall’errore (assoluto o relativo) Errore assoluto = valore osservato – valore vero. valore osservato – valore vero. Errore relativo = x100. valore vero.")
4
Errore casuale o indeterminato
L’errore casuale ha pari probabilità di essere positivo o negativo (dispersione dei dati più o meno simmetrica intorno al valore medio) e non può essere corretto.
 e non può essere corretto.")
5
Distribuzione dei risultati sperimentali
Nella maggior parte degli esperimenti analitici quantitativi la distribuzione dei dati replicati è simile a quella di una curva gaussiana e questo perché la deviazione dalla media è conseguente all’errore casuale

6
Il trattamento statistico dell’errore casuale -(x - µ)2 /22 e y =
Popolazione: è l’insieme di tutte le misure Campione: sottoinsieme della popolazione selezionato per l’analisi e rappresentativo della popolazione stessa Curva normale di errore di una popolazione -(x - µ)2 /22 e y = 2 µ = media della popolazione = deviazione standard della popolazione N (xi - µ)2 i=1 = N
2 /22. e. y = 2 µ = media della popolazione. = deviazione standard della popolazione. N. (xi - µ)2. i=1. = N.")
7
(xi - x)2 s = (N-1)= gradi di libertà N-1
La deviazione std. di un campione La media di un campione è indicata con x e la d.s con s N (xi - x)2 s i=1 = (N-1)= gradi di libertà N-1 La varianza = s2 deviazione std. relativa = s / x Coefficiente di variazione (CV%) = (s / x) 100
2. s. i=1. = (N-1)= gradi di libertà. N-1. La varianza = s2. deviazione std. relativa = s / x. Coefficiente di variazione (CV%) = (s / x) 100.")
8
Intervallo di fiducia = x
Intervalli di fiducia In analisi farmaceutica solitamente non si determina la media e d.s. di una popolazione bensì di un campione rappresentativo E’ tuttavia possibile con l’analisi statistica determinare un intervallo di fiducia attorno ad x nel quale si prevede di determinare il valore medio µ con una certa probabilità (dal 95%) L’intervallo di fiducia per una media x è quindi l’intervallo entro il quale ci si aspetta di trovare, con una certa probabilità, la media µ della popolazione (le linee di confine sono chiamati i limiti di fiducia) Trovare l’intervallo di fiducia quando è nota o quando s è una buona stima di z Intervallo di fiducia = x N
 L’intervallo di fiducia per una media x è quindi l’intervallo entro il quale ci si aspetta di trovare, con una certa probabilità, la media µ della popolazione (le linee di confine sono chiamati i limiti di fiducia) Trovare l’intervallo di fiducia quando è nota o quando s è una buona stima di z Intervallo di fiducia = x. N.")
9
t s x N z Trovare l’intervallo di fiducia quando non è nota

10
Esempio di calcolo degli intervalli di fiducia
Si considerino i seguenti risultati relativi al contenuto di alcol etilico in un campione di sangue: 0.084%, 0.089%, 0.079%. Calcolare l’intervallo di fiducia per la media al 95% assumendo che dalle esperienze precedenti acquisite su un centinaio di campioni, si sa che la deviazione std. del metodo s= 0.005% è una buona stima di I tre risultati ottenuti rappresentano il solo modo per valutare le precisione del metodo Caso A z 1.96 0.005 Intervallo di fiducia (95%) = x = 0.084 = 0.084 0.006% N 3 0.078 0.09
 = x. = = 0.006% N")
11
Caso B s = 0.005% t s 4.303 0.005 Intervallo di fiducia (95%) = x = 0.084 = 0.084 0.012% N 3 0.072 0.096

12
Confronto di medie utilizzando la t di Student
Il test t viene utilizzato per confrontare due seri di misure al fine di decidere se sono o non sono significativamente differenti tra loro Il test si basa sull’ipotesi nulla che postula che le due serie di misure siano uguali H0 : µ = µ0 per convenzione, si rifiuta l’ipotesi nulla quando la probabilità che la differenza tra le due serie di misure sia casuale è inferiore al 5% (p<0.05) Confronto tra le media sperimentale ed il valore noto: x – valore noto tcalcolata = N s Se tcalcolata > ttabulata (al 95%) la differenza è significativa
 Confronto tra le media sperimentale ed il valore noto: x – valore noto. tcalcolata = N. s. Se tcalcolata > ttabulata (al 95%) la differenza è significativa.")
13
Esempio di confronto di una serie di misure con un valore noto
Si consideri un nuovo metodo analitico che viene applicato ad uno std. di riferimento (valore noto= 3.19%). I valori ottenuti sono i seguenti: 3.29%, 3.22%, 3.30%, 3.23% (x = 3.26; s= 0.04). Il metodo è accurato? (il risultato è in accordo con il valore noto?) 3.26 – 3.19 tcalcolata = 4 = 3.41 0.04 Poiché tcalcolata (3.41) > ttabulata (3.182) il risultato ottenuto è differente da quello noto. La possibilità di commettere un errore nel trarre questa conclusione è minore del 5%
. I valori ottenuti sono i seguenti: 3.29%, 3.22%, 3.30%, 3.23% (x = 3.26; s= 0.04). Il metodo è accurato (il risultato è in accordo con il valore noto ) 3.26 – tcalcolata = 4. = Poiché tcalcolata (3.41) > ttabulata (3.182) il risultato ottenuto è differente da quello noto. La possibilità di commettere un errore nel trarre questa conclusione è minore del 5%")
14
tcalcolata = x1 – x2 scomune n1n2 n1 + n2 scomune =
Confronto di misure ripetute (test t non accoppiato) Si considerino una serie di dati che consistono di n1 e n2 misure (aventi la media x1 e x2) tcalcolata = x1 – x2 scomune n1n2 n1 + n2 scomune = s12(n1 -1)+ s22(n2-1) n1+ n2 -2 massa gas isolati aria: x1= g; s1= (n1=7) massa gas per via chimica: x2= g; s2= (n1=8) n.b gradi di libertà = (n1+n2) -1 scomune= tcalcolata= 20.2 Poiché tcalcolata > ttabulata (95%, ttabulata compresa tra e 2.131) la è significativa
 Si considerino una serie di dati che consistono di n1 e n2 misure (aventi la media x1 e x2) tcalcolata = x1 – x2. scomune. n1n2. n1 + n2. scomune = s12(n1 -1)+ s22(n2-1) n1+ n2 -2. massa gas isolati aria: x1= g; s1= (n1=7) massa gas per via chimica: x2= g; s2= (n1=8) n.b gradi di libertà = (n1+n2) -1. scomune= tcalcolata= Poiché tcalcolata > ttabulata (95%, ttabulata compresa tra e 2.131) la è significativa.")
15
(di - d)2 d tcalcolata= N sd = sd N-1 sd = 0.122 0.060 tcalcolata =
Confronto di singole differenze (test t accoppiato) Questo è il caso in cui si utilizzano due metodi differenti per effettuare singole misure sugli stessi campioni N (di - d)2 d tcalcolata= N sd i=1 = sd N-1 d è la differenza media tra le due serie di dati e n è il numero di coppie di dati sd = 0.122 0.060 tcalcolata = 6 = 1.20 0.122 Dato che tcalcolata<ttabulata (2.571 per un livello di f. al 95% e 5 gradi di libertà) i due metodi non sono significativamente diversi tra loro
 Questo è il caso in cui si utilizzano due metodi differenti per effettuare singole misure sugli stessi campioni. N. (di - d)2. d. tcalcolata= N. sd. i=1. = sd. N-1. d è la differenza media tra le due serie di dati e n è il numero di coppie di dati. sd = tcalcolata = 6. = Dato che tcalcolata<ttabulata (2.571 per un livello di f. al 95% e 5 gradi di libertà) i due metodi non sono significativamente diversi tra loro.")
16
Il Test F per il confronto delle deviazioni std.
Il test t permette di confrontare le medie e quindi di rilevare l’errore sistemico Se si vuole confrontare la precisione si devono confrontare le deviazioni std. con il test F s12 Si pone la d.s. maggiore al numeratore in modo che F1 Se Fcalcolata > Ftabulata allora la è significativa Fcalcolata= s22

17
Il Test Q per i dati sospetti (outliers)
talvolta data una serie di misure, un dato risulta non essere consistente con gli altri a causa di un errore grossolano si può usare il test Q per decidere di mantenere o scartare il dato sospetto Qcalcolata = divario intervallo Intervallo: la differenza tra valori estremi Divario: la differenza fra il valore sospetto e quello più vicino Se Qcalcolata>Qtabulata il dato sospetto andrebbe eliminato Esempio divario = 0.11 Qcalcolata: 0.11/0.2 = 0.55 Poiché Qcalcolata<Qtabulata il dato deve essere mantenuto Intervallo = 0.2

18
Analisi della varianza (ANOVA)
L’analisi della varianza permette di confrontare più di due medie di campioni Si considerino 4 serie di dati e le 4 medie delle popolazione µ1, µ2, µ3, µ4 L’ipotesi nulla di ANOVA : H0: µ1= µ2 = µ3 = µ4 L’ipotesi alternativa: almeno due medio tra loro Alcuni esempi di applicazione ANOVA: - vi è differenza nei risultati ottenuti da 5 analisti nella determinazione del Ca2+ ? - quattro composizioni di solventi hanno influenza sulla reazione? - I risultati delle determinazioni di Manganese sono usando tre metodi analitici? - Ci sono differenze nella fluorescenza di uno ione complesso a 6 valori di pH? Il fattore è la variabile indipendente la risposta è la variabile dipendente

19
Quando sono coinvolti più di un fattore si utilizza ANOVA a due vie (es. effetto della temperatura e pH sulla velocità di reazione) Il principio dell’ANOVA è di confrontare la variazione tra i diversi livelli (i valori del fattore) rispetto alla variazione all’interno di ciascun gruppo L’ipotesi nulla è vera quando le variazioni tra le medie dei gruppi è simile alla variazione all’interno dei gruppi L’ipotesi nulla è falsa quando la variazione tra le medie dei gruppi è > rispetto alle variazione tra i singoli gruppi
 rispetto alla variazione all’interno di ciascun gruppo. L’ipotesi nulla è vera quando le variazioni tra le medie dei gruppi è simile alla. variazione all’interno dei gruppi. L’ipotesi nulla è falsa quando la variazione tra le medie dei gruppi è > rispetto alle variazione tra i singoli gruppi.")
20
( ) ( ) ( ) x N1 N2 Ni x = x1 + x2 + ….. xi N N N
In primo luogo si deve stimare la variazione tra i gruppi e all’interno del singolo gruppo nel seguente modo 1. Si calcola il valore medio complessivo x ( N1 ) ( N2 ) ( Ni ) x = x1 + x2 + ….. xi N N N Il valore può anche essere determinato sommando tutti i dati e dividendo per N 2. La variazione tra i gruppi si determina calcolando la somma dei quadrati dovuti al fattore SQF = N1( )2 + N2( )2 + ……..Ni ( )2 x1 - x x2 - x xi - x SQF Quadrato della media dei livelli del fattore = QMF = I -1 I = numero dei fattori
 ( N2. ) ( Ni. ) x. = x1. + x2. + ….. xi. N. N. N. Il valore può anche essere determinato sommando tutti i dati e dividendo per N. 2. La variazione tra i gruppi si determina calcolando la somma dei quadrati dovuti al fattore. SQF = N1( )2 + N2( )2 + ……..Ni ( )2. x1 - x. x2 - x. xi - x. SQF. Quadrato della media. dei livelli del fattore. = QMF. = I -1. I = numero dei fattori.")
21
SQE = (N1-1)s12 + (N2-1)s22 …. (Ni-1)si2
3. La variazione all’interno dei gruppi viene determinata calcolando la somma dei quadrati dell’errore SQE = (N1-1)s12 + (N2-1)s22 …. (Ni-1)si2 SQE Errore del quadrato della media = EQM = N -n N= numero analisi; n= numero di fattori QMF F = EQM L’ipotesi nulla è scartata quando Fcalcolato > Ftabulato
s12 + (N2-1)s22 …. (Ni-1)si2. SQE. Errore del quadrato della media. = EQM. = N -n. N= numero analisi; n= numero di fattori. QMF. F = EQM. L’ipotesi nulla è scartata quando Fcalcolato > Ftabulato.")
22
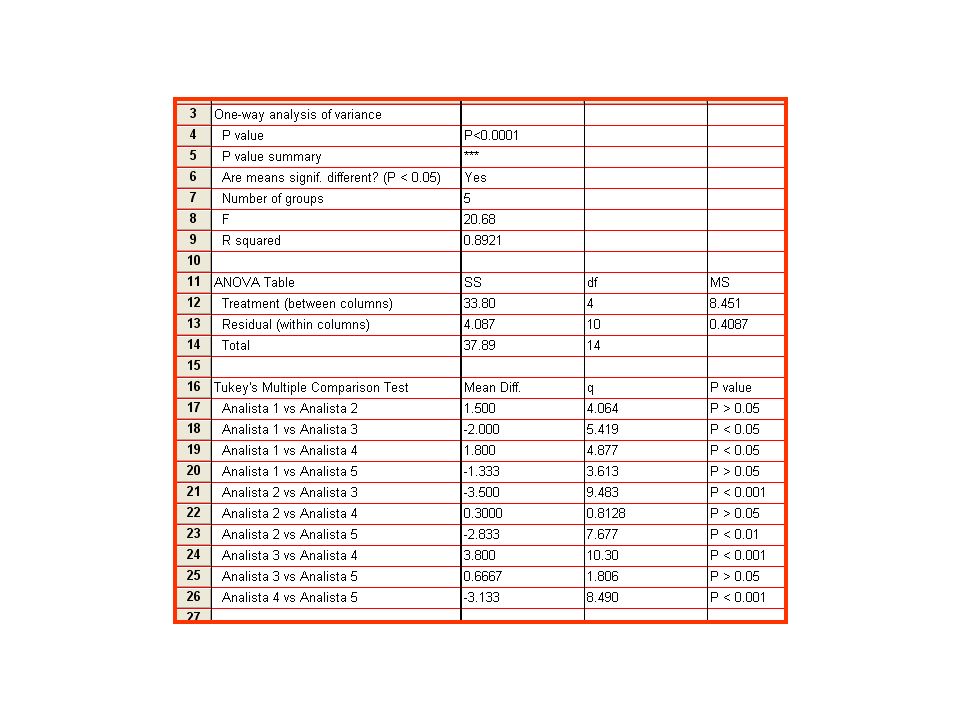
Applicazioni analisi ANOVA
N. Prova Analista 1 Analista 2 Analista 3 Analista 4 Analista 5 1 10.3 9.5 12.1 9.6 11.6 2 9.8 8.6 13.0 8.3 12.5 3 11.4 8.9 12.4 8.2 Media 10.5 9 8.7 11.833 Dev. Std. Ad un livello del 95%, le medie sono diverse? x = mmoli Ca2+ SQF= (5-1= 4 gradi di libertà); QMF= /4= SQE= (15-5= 10 gradi di libertà); EQM= = Fcalcolato= / = 20.68
; QMF= /4= SQE= (15-5= 10 gradi di libertà); EQM= = Fcalcolato= / =")
23
Dato che Fcalcolato>Ftabulato (livello di fiducia al 95%)
Scartiamo H0 quindi esiste un differenza significativa Tra quali gruppi esiste una differenza significativa?: Post-test

24
Bonferroni, Tukey: compara tutte le colonne
Dunnett: compara tutte le colonne vs il controllo

26
L’uso di fogli di calcolo in analisi chimica
Cella attiva celle Foglio di lavoro Le celle possono contenere testo, numeri o formule

27
In Excel le formule iniziano con il segno =
Alcune funzioni statistiche preimpostate

28
Uso di $ per variabili statiche

29
Valore accettato = 122.6 Il metodo è accurato?

31
Esperimento di Rayleigh
(Es. di test non accoppiato)
")
32
Esperimento di Rayleigh
RISULTATO TEST T

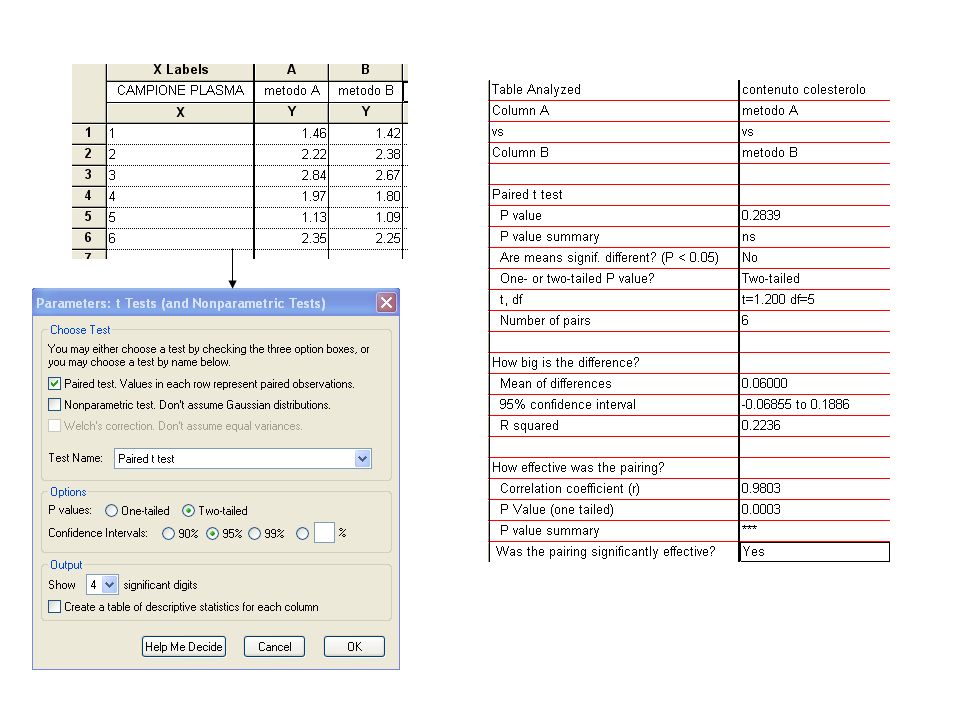
33
Un test accoppiato : è appropriato qualora esista un naturale appaiamento tra le osservazioni dei campioni, quale il caso di una duplice verifica di un gruppo campione o prima e dopo un esperimento. È necessario che i due intervalli di input contengano lo stesso numero di dati. Un test non accoppiato: quando non esiste un appaiamento tra le due serie di misure. Le misure posso anche avere una numerosità differente Test a una o due code: Date due serie di misure le cui medie sono X1 e X2, si scegli il test a una coda quando l’ipotesi alternativa è x1 > x2 (oppure x1< x2). Il test a una coda si utilizza quando misure precedenti, limiti fisici o il buon senso indica che se esiste una differenza questa può andare in una sola direzione. Il test a due code si utilizza quando la differenza può andare in entrambe le direzioni e quindi x1 x2
. Il test a una coda si utilizza quando misure precedenti, limiti fisici o il buon senso indica che se esiste una differenza questa può andare in una sola direzione. Il test a due code si utilizza quando la differenza può andare in entrambe le direzioni e quindi x1 x2.")
Presentazioni simili



 e nel verificare se con i dati a disposizione è possibile rifiutarla o no.>")


>")













