Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
Operazioni di campionamento CAMPIONAMENTO Tutte le operazioni effettuate per ottenere informazioni sul sito /area da monitorare (a parte quelle di analisi) CAMPIONAMENTO può essere spaziale o temporale CAMPIONAMENTO può fornire data set UNIVARIATO o MULTIVARIATO (una misura per campione o più misure per campione)
 CAMPIONAMENTO può essere spaziale o temporale CAMPIONAMENTO può fornire data set UNIVARIATO o MULTIVARIATO (una misura per campione o più misure per campione)")
2
DEFINIZIONE DI POPOLAZIONE E SAMPLE OBIETTIVO: Dal set di dati vogliamo informazioni certe sulla popolazione PROBLEMI: 1)La dimensione del sample è sempre inferiore alla popolazione 2)I dati ottenuti sono affetti da errori o margini di incertezza NON ELIMINABILI TERRENO n CAMPIONI DATI POPOLAZIO NE SAMPLE (campione) SET di DATI
La dimensione del sample è sempre inferiore alla popolazione 2)I dati ottenuti sono affetti da errori o margini di incertezza NON ELIMINABILI TERRENO n CAMPIONI DATI POPOLAZIO NE SAMPLE (campione) SET di DATI")
3
PROBLEMA: da un campione otteniamo n dati analitici diversi tra loro qual’è quello vero? che relazione c’è tra i valori misurati e quello vero? Le misure che facciamo sono VARIABILI ALEATORIE caratterizzate da: INTERVALLO DI VARIAZIONE DISTRIBUZIONE DI PROBABILITA’ Noi possiamo solo: stimare il valore “vero” di queste variabili stimare la probabilità che il valore vero sia all’interno di un certo intervallo descrivere in modo statistico il data-set verificare delle ipotesi Variabili aleatorie

4
PARAMETRI STATISTICI MEDIA MEDIANA (50° percentile) Valore centrale di una serie di n numeri ordinata in modo crescente o decrescente Se n è pari bisogna definire il criterio di valutazione (valore medio, inferiore o maggiore) DEVIAZIONE STANDARD VARIANZA
 Valore centrale di una serie di n numeri ordinata in modo crescente o decrescente Se n è pari bisogna definire il criterio di valutazione (valore medio, inferiore o maggiore) DEVIAZIONE STANDARD VARIANZA")
5
PERCENTILE Il calcolo dell‘n.esimo percentile deve essere effettuato a partire dai valori effettivamente misurati. Tutti i valori saranno riportati in un elenco in ordine crescente: X 1 < o = X 2 < o = X 3 < o =.. < o =X k < o =.. < o = X N-1 < o = X N L'n.esimo percentile è il valore dell'elemento di rango k, per il quale k viene calcolato per mezzo della formula seguente: k = (q * N) q = n/100 N = numero dei valori effettivamente misurati. Il valore di (q * N) viene arrotondato al numero intero più vicino.
 q = n/100 N = numero dei valori effettivamente misurati. Il valore di (q * N) viene arrotondato al numero intero più vicino..")
6
CENNI DI TEORIA DEGLI ERRORI DEFINIZIONE DI ERRORE : L’errore è lo scostamento tra la misura ed il valore vero ERRORE = MISURA - VALORE VERO CLASSIFICAZIONE ERRORI grossolani (da non fare!) sistematici casuali La teoria statistica degli errori si occupa solo degli errori sistematici e casuali
 sistematici casuali La teoria statistica degli errori si occupa solo degli errori sistematici e casuali")
7
ERRORI SISTEMATICI ( ) Rappresentano una tendenza deterministica a SOVRASTIMARE o SOTTOSTIMARE il valore vero Gli errori sistematici hanno cause ben precise che possono anche essere individuate e rimosse (strumento non calibrato, insufficiente purezza dei reagenti utilizzati...) è la media delle misure ERRORI CASUALI ( ) E’ dato dalla somma di tutte le IMPREVEDIBILI variazioni nella esecuzione delle varie operazioni analitiche che determinano un certo scostamento della misura dal valore medio delle misure stesse
 Rappresentano una tendenza deterministica a SOVRASTIMARE o SOTTOSTIMARE il valore vero Gli errori sistematici hanno cause ben precise che possono anche essere individuate e rimosse (strumento non calibrato, insufficiente purezza dei reagenti utilizzati...) è la media delle misure ERRORI CASUALI ( ) E’ dato dalla somma di tutte le IMPREVEDIBILI variazioni nella esecuzione delle varie operazioni analitiche che determinano un certo scostamento della misura dal valore medio delle misure stesse")
8
Totale=Sistematico+Casuale =+ = + ERRORE TOTALE E’ dato dalla somma degli errori sistematici e casuali ACCURATEZZA = scostamento del valore medio delle misure dal valore reale (dipende dagli errori sistematici e quindi dalla media) PRECISIONE o RIPETIBILITA’= scostamento dei dati dal valore medio (dipende dagli errori casuali dipende dalla deviazione standard)
 PRECISIONE o RIPETIBILITA’= scostamento dei dati dal valore medio (dipende dagli errori casuali dipende dalla deviazione standard)")
9
PRECISIONE o RIPETIBILITA’ ACCURATEZZA Misura accurata e precisa Misura né accurata né precisa

10
Utilizzati per interpretare fenomeni Statistica descrittiva Utilizzati per effettuare inferenze ottenere informazioni su nature e/o valori dei parametri delle v.a. Gaussiana Chi-quadrato t-Student Fisher MODELLI DI VARIABILI ALEATORIE

11
PROBABILITA’ E FUNZIONI DI DISTRIBUZIONE DI PROBABILITA ’ Data una v.a. X si definisce la funzione distribuzione cumulata (Cdf) F(x) che rappresenta la probabilità che la v.a. assuma un valore inferiore a x Risulta e Se la v.a. è continua per esprimere la probabilità che la v.a. assuma valori prossimi ad un determinato x si definisce la funzione densità di probabilità (pdf)
 F(x) che rappresenta la probabilità che la v.a. assuma un valore inferiore a x Risulta e Se la v.a. è continua per esprimere la probabilità che la v.a. assuma valori prossimi ad un determinato x si definisce la funzione densità di probabilità (pdf).")
12
PROBABILITA’ E FUNZIONI DI DISTRIBUZIONE DI PROBABILITA’ Dalle definizioni precedenti risulta:

13
Distribuzione normale o Gaussiana E’ il modello di v.a. più adoperato. Può essere definita come: modello interpretativo degli errori o scostamenti da un valore medio Introducendo la v.a. Gaussiana standard (o ridotta) che esprime gli errori di misura come multipli della loro ampiezza e ipotizzando che: sia nulla la media degli errori la pdf degli errori sia simmetrica e tenda a zero per +/- infinito la pdf abbia un unico massimo in corrispondenza del valore nullo di U si ottiene la pdf:
 che esprime gli errori di misura come multipli della loro ampiezza e ipotizzando che: sia nulla la media degli errori la pdf degli errori sia simmetrica e tenda a zero per +/- infinito la pdf abbia un unico massimo in corrispondenza del valore nullo di U si ottiene la pdf:.")
14
che rispetto alla v.a. X diventa In caso di elaborazioni di valori discreti si può utilizzare la espressione: Dove Y è il n° di osservazioni o valori all’interno di un certo intervallo di ampiezza i ed n è il n° totale di osservazioni

15
L’area sottesa tra –x e x è pari a 1-2 x= area tra –x e +x =0.68 x=2 area tra –x e +x =0.95 x=3 area tra –x e +x =0.997

16
Modello di v.a. Log-normale Se la pdf non può che essere asimmetrica (ad esempio una variabile che assume solo valori positivi) cade una delle ipotesi della gaussiana. Si definisce una distribuzione Log-normale: una v.a. Y tale che il suo log è una v.a. Normale z di parametri e La sua p.d.f. è
 cade una delle ipotesi della gaussiana. Si definisce una distribuzione Log-normale: una v.a. Y tale che il suo log è una v.a. Normale z di parametri e La sua p.d.f. è.")
17
Modello di v.a. Log-normale

18
Esercizio par. 10.8 distribuzione Log-normale Abbiamo la seguente distribuzione della concentrazione di un campione (curva a istogramma) molto asimmetrica. Se proviamo a modellarla assumendo una distribuzione normale otteniamo la curva in blu Se facciamo il lnC otteniamo una distribuzione più vicina a una normale x(lnC)= 2.44 (lnC)=0.89
 molto asimmetrica. Se proviamo a modellarla assumendo una distribuzione normale otteniamo la curva in blu Se facciamo il lnC otteniamo una distribuzione più vicina a una normale x(lnC)= 2.44 (lnC)=0.89.")
19
Esercizio par. 10.8 distribuzione Log-normale La pdf utilizzando il modello di variabile aleatoria lognormale è riportata in figura (curva rossa) Come si osserva il fitting è migliore di quello ottenuto assumendo come modello una distribuzione normale I parametri sono: x g = 11.46 g = 2.43 il 68.3% dei dati si trova tra 4.72 e 27.83
 Come si osserva il fitting è migliore di quello ottenuto assumendo come modello una distribuzione normale I parametri sono: x g = g = 2.43 il 68.3% dei dati si trova tra 4.72 e")
20
INTERVALLO DI CONFIDENZA (IC o LC) E’ un intervallo di valori all’interno del quale il valore reale si trova con una certa probabilità a questo scopo si usano diversi modelli di variabili aleatorie Per calcolare IC diSi usa Mediat-Student VarianzaChi-quadrato Rapporto di varianzeFisher
 E’ un intervallo di valori all’interno del quale il valore reale si trova con una certa probabilità a questo scopo si usano diversi modelli di variabili aleatorie Per calcolare IC diSi usa Mediat-Student VarianzaChi-quadrato Rapporto di varianzeFisher")
21
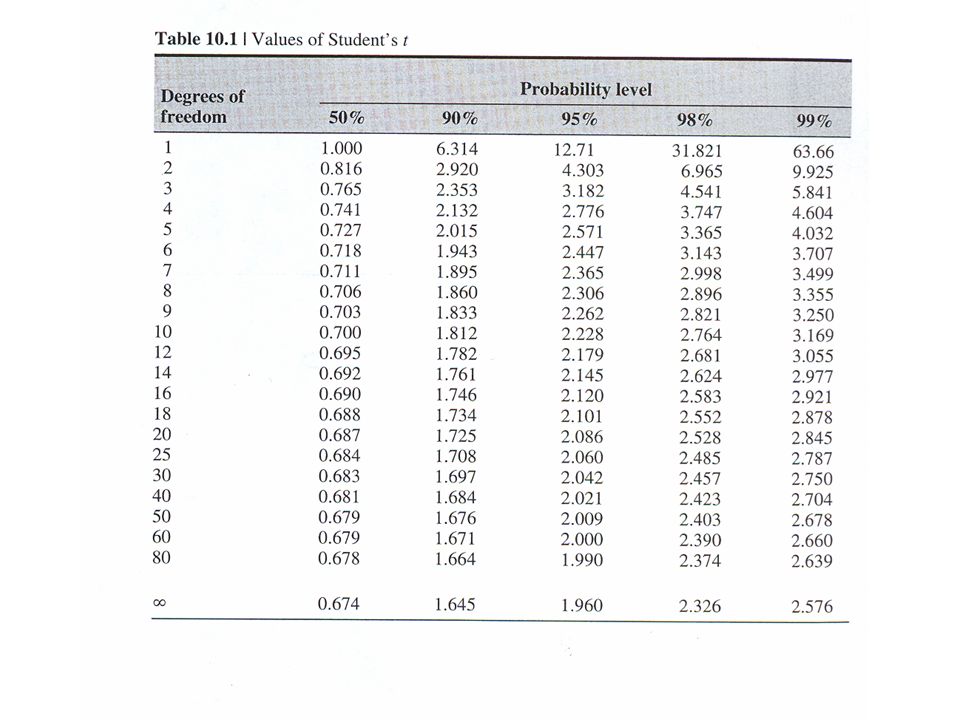
IC della media dove:t = variabile t-Student s = deviazione standard stimata n = gradi di libertà (numero di valori - 1) Il valore del parametro statistico t si ricava da tabelle in funzione di n e dell’intervallo desiderato (ad es. 95% o 90% etc.). Al crescere del numero di valori (n-1) l’ampiezza dell’intervallo diminuisce, sia perchè cresce il denominatore sia perchè diminuisce il valore di t = valore medio stimato
. Al crescere del numero di valori (n-1) l’ampiezza dell’intervallo diminuisce, sia perchè cresce il denominatore sia perchè diminuisce il valore di t = valore medio stimato.")
24
IC per una variabile Log-normale Per una v.a. Log- normale l’intervallo di confidenza si calcola come IC del rapporto di varianze Si utilizza la distribuzione di Fisher F: Definito l’IC si legge dalla tabella in funzione dei gradi di libertà con cui sono state calcolate le 2 varianze il valore del loro rapporto F.

25
TEST DELLE IPOTESI I problemi che si intendono risolvere sono del tipo: se la differenza che si registra tra la media calcolata ed il valore “vero” è significativa o meno. se la differenza che si registra tra due valori medi è significativa o meno. Con metodi statistici si verifica se l’ipotesi è: non respinta (accettabile) oppure respinta In statistica i test verificano in termini probabilistici la validità di una ipotesi detta ipotesi nulla (o ipotesi zero indicata con H 0 ) se l’ipotesi viene rifiutata si accetta l’ipotesi alternativa (H 1 )
 oppure respinta In statistica i test verificano in termini probabilistici la validità di una ipotesi detta ipotesi nulla (o ipotesi zero indicata con H 0 ) se l’ipotesi viene rifiutata si accetta l’ipotesi alternativa (H 1 ).")
26
La differenza è significativa se: La differenza non è significativa se: Confronto tra media e valore reale Si intende verificare se la differenza tra valore medio e valore reale è significativa o meno. Si valuta

27
Confronto tra due medie verifica del risultato di due diverse metodiche di analisi sullo stesso campione verifica di due diversi set di dati (dati di due stazioni di monitoraggio relative allo stesso inquinante) Si vuole verificare se la differenza dei due valori medi è statisticamente significativa (ipotesi nulla) o meno (ipotesi alternativa). Si valuta La differenza è significativa se: (altrimenti non è significativa)
.")
Presentazioni simili


 e nel verificare se con i dati a disposizione è possibile rifiutarla o no.>")











>")





