Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
Scale di misura delle variabili
Qualitative: nominali o ordinali l’unico parametro valutabile è la proporzione Quantitative: intervalli o rapporti possono essere eseguiti dei calcoli, i parametri valutabili sono molti (statistiche descrittive numeriche: misure di posizione e di dispersione) possono essere discrete o continue.
 possono essere discrete o continue.")
2
Richiami di statistica descrittiva
Descrivere e sintetizzare i dati osservati attraverso grafici (es. distribuzioni di frequenza), indici di posizione e dispersione Dati univariati Dati bivariati Dati multivariati
, indici di posizione e dispersione. Dati univariati. Dati bivariati. Dati multivariati.")
3
Indici di posizione Indicano la tendenza centrale di un insieme di dati Media aritmetica Proprietà della media aritmetica: la sommatoria degli scarti di ogni dato dalla media (momento di 1° ordine) è nulla. la sommatoria del quadrato degli scarti (momento di 2° ordine) è minima (ovvero non esiste alcun altro punto che sostituito alla media dia un valore inferiore
 è nulla. la sommatoria del quadrato degli scarti (momento di 2° ordine) è minima. (ovvero non esiste alcun altro punto che sostituito alla media dia un valore inferiore.")
4
Indici di posizione media aritmetica
Se i dati sono espressi come frequenze: media aritmetica ponderata Se i dati sono espressi come proporzioni:

5
Indici di posizione Mediana: divide la serie ordinata in due parti di uguale numerosità Moda: è il valore della classe a cui corrisponde la maggiore frequenza. Media armonica: è il reciproco della media dei reciproci, idonea a mediare rapporti tra 2 variabili. Media geometrica: è la radice ennesima del prodotto di n dati. Idonea per mediare tassi.

6
Indici di tendenza centrale resistenti
Trimmed mean: media aritmetica nella quale non vengono considerate le code della distribuzione (es. il 5% dei dati) M-estimators (Maximum likelihood estimators): media aritmetica pesata con peso funzione della distanza dal valore centrale. Si differenziano per la funzione di assegnazione dei pesi.
 M-estimators (Maximum likelihood estimators): media aritmetica pesata con peso funzione della distanza dal valore centrale. Si differenziano per la funzione di assegnazione dei pesi.")
7
Indici di dispersione Quantili: misure di posizione non centrale. Sono valori che dividono la serie ordinata in un certo numero di parti di uguale numerosità. Percentili: dividono la serie ordinata in 100 parti uguali. Il p-esimo percentile di una distribuzione è quel valore con p% dei valori inferiori ad esso. In statistica inferenziale sono interessanti il 1, 2.5, 5, 95, 97.5 e 99 esimo percentile Quartili dividono la serie ordinata in 4 parti uguali. Sono il 25 esimo, il 50 esimo (è la mediana) e il 75 esimo percentile L’intervallo tra il 25 esimo e il 75 esimo percentile si chiama distanza interquartile. Decili: dividono la serie ordinata in 10 parti uguali. Sono il 10, …80, 90 percentile.
 e il 75 esimo percentile. L’intervallo tra il 25 esimo e il 75 esimo percentile si chiama distanza interquartile. Decili: dividono la serie ordinata in 10 parti uguali. Sono il 10, …80, 90 percentile.")
8
Indici di dispersione Campo di variazione (Range): Xmax - Xmin
Scarti dalla media Devianza (Sum of Squares) Varianza (o Quadrato Medio o Mean Square) Se i dati sono in frequenze: Se i dati sono in proporzioni:
 Varianza (o Quadrato Medio o Mean Square) Se i dati sono in frequenze: Se i dati sono in proporzioni:")
9
Indici di dispersione Deviazione standard (standard deviation)
Coefficiente di variazione (CV)
")
10
Indici di dispersione Teorema di Tchebysheff: indipendentemente dalla distribuzione, fissata una costante K, l’intervallo contiene almeno [1-(1/K2)] dati. (s è la dev.standard) Es. K = 2 l’intervallo contiene almeno il 75% dei dati K = 3 l’intervallo contiene almeno l’ 89% dei dati Approssimativamente, se una distribuzione è simmetrica e a campana: l’intervallo contiene il 68% dei dati l’intervallo contiene il 95% dei dati l’intervallo contiene quasi il 100% dei dati
] dati. (s è la dev.standard) Es. K = 2 l’intervallo contiene almeno il 75% dei dati. K = 3 l’intervallo contiene almeno l’ 89% dei dati. Approssimativamente, se una distribuzione è simmetrica e a campana: l’intervallo contiene il 68% dei dati. l’intervallo contiene il 95% dei dati. l’intervallo contiene quasi il 100% dei dati.")
11
Indici di forma Asimetria (Skewness) negativa positiva
Curtosi (Kurtosis) platicurtica leptocurtica
 platicurtica. leptocurtica.")
12
Cambio di scala dei dati
Se trasformo una variabile: a = cambio di origine b = cambio di scala La media e la varianza vengono trasformate nel modo seguente: Aggiungere una costante ai dati non ha effetto sulla loro varianza

13
Analisi esplorativa dei dati
Tra i più comuni strumenti grafici (oltre ai bar charts e histograms) della EDA sono i diagrammi stem and leaf e box plot diagramma stem and leaf 2.2 , 2.2, 3.1, 3.1, 3,3, 3,4, 4.2, 4,6, 4,7, 4.8, 5 5.1 Si considerano le prime 2 cifre significative ( in questo caso l’intero numero). la prima cifra costituisce lo stem, la seconda le leaf. 2 22 3 1134 4 2678 5 01 si ottiene una specie di distribuzione di frequenza
 della EDA sono i diagrammi stem and leaf e box plot. diagramma stem and leaf. 2.2 , 2.2, 3.1, 3.1, 3,3, 3,4, 4.2, 4,6, 4,7, 4.8, Si considerano le prime 2 cifre significative ( in questo caso l’intero numero). la prima cifra costituisce lo stem, la seconda le leaf si ottiene una specie di distribuzione di frequenza.")
14
Stem-and-Leaf Plot Frequency Stem & Leaf 7, 13, 14, 7, 9, 1, , 3, 2, 8,00 Extremes (>=10,8) Stem width: ,0 Each leaf: case(s)
 Stem width: 1,0. Each leaf: 1 case(s)")
15
Box plot Outlayer (>3*diff int) Outlayer (<3*diff int)
1,5 * diff. interquartile 3° quartile mediana 1° quartile La mediana e il box indicano asimmetria nella parte centrale della distribuzione, i bracci presenza di “code”

16
Inferenza statistica Popolazione e campione
POPOLAZIONE: insieme di tutte le manifestazioni relative a un certo fenomeno. Può essere finita o infinita. In genere ci si occupa di popolazioni molto grandi. CAMPIONE: sottoinsieme della popolazione. Se estratto casualmente rappresenta la popolazione in esame.

17
Obiettivi dell’inferenza statistica
Test delle ipotesi Stima dei parametri della popolazione

18
Probabilità: definizioni
Spazio campione: insieme di tutti i possibili risultati o realizzazioni ottenibili. Realizzazione (outcome): risultato specifico ottenuto. Evento: combinazione di realizzazioni, che ha caratteristiche specifiche di interesse. Esempi spazio campione del lancio di un dado: 1, 2, 3, 4, 5, 6 spazio campione del lancio di 2 dadi:
: risultato specifico ottenuto. Evento: combinazione di realizzazioni, che ha caratteristiche specifiche di interesse. Esempi. spazio campione del lancio di un dado: 1, 2, 3, 4, 5, 6. spazio campione del lancio di 2 dadi:")
19
Probabilità: definizioni
La probabilità di un evento A è indicata da P(A) ed è sempre compresa tra 0 e 1 Se due eventi si escludono l’un l’altro, sono detti mutualmente esclusivi. La somma delle probabilità di tutti gli eventi mutualmente esclusivi deve essere = 1 Il complemento di un evento è il non verificarsi di tale evento. Il complemento di A è indicato con Ā P(Ā) = 1 - P(A) Due eventi A e B sono detti indipendenti se la probabilità che si verifichi A non è influenzata dal fatto che si sia verificato B o viceversa.
 ed è sempre compresa tra 0 e 1. Se due eventi si escludono l’un l’altro, sono detti mutualmente esclusivi. La somma delle probabilità di tutti gli eventi mutualmente esclusivi deve essere = 1. Il complemento di un evento è il non verificarsi di tale evento. Il complemento di A è indicato con Ā. P(Ā) = 1 - P(A) Due eventi A e B sono detti indipendenti se la probabilità che si verifichi A non è influenzata dal fatto che si sia verificato B o viceversa.")
20
Regole per combinare le probabilità P(A or B)= P(A)+P(B) - P(A and B)
Per combinare le probabilità di più eventi valgono le seguenti regole Se due eventi sono indipendenti, la probabilità che entrambi si verifichino è: P(A and B)= P(A)P(B) La probabilità che si verifichi almeno uno dei due eventi è: P(A or B)= P(A)+P(B) Se i due eventi non sono mutualmente esclusivi: P(A or B)= P(A)+P(B) - P(A and B)
= P(A)P(B) La probabilità che si verifichi almeno uno dei due eventi è: P(A or B)= P(A)+P(B) Se i due eventi non sono mutualmente esclusivi: P(A or B)= P(A)+P(B) - P(A and B)")
21
Distribuzioni di probabilità
Variabile casuale: numero che viene assegnato a ciascuna realizzazione di un esperimento Distribuzione di probabilità: probabilità associate a ciascun valore della variabile casuale La variabile casuale può essere discreta o continua Distribuzioni di probabilità discrete (di VC discrete) Distribuzioni di probabilità continue (di VC continue) La distribuzione di probabilità è la distribuzione teorica della popolazione, i cui parametri si intendono indagare La media di una distribuzione di probabilità è detta valore atteso della variabile casuale
 Distribuzioni di probabilità continue (di VC continue) La distribuzione di probabilità è la distribuzione teorica della popolazione, i cui parametri si intendono indagare. La media di una distribuzione di probabilità è detta valore atteso della variabile casuale.")
22
Distribuzioni di probabilità della somma di due dadi da gioco ERRORE NEL GRAFICO DATI TRUCCATI!
0.18 0.16 0.14 0.12 0.1 NORMALI 0.08 TRUCCATI 0.06 0.04 0.02 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16

23
Distribuzioni di probabilità discrete
p(y) 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16 0.18 2 3 4 5 6 7 8 9 10 11 12 0 p(y) 1 p(y) = 1 Valore medio (valore atteso): = y p(y) Varianza: 2= (y- )2p(y) y 1
 p(y) 1. p(y) = 1. Valore medio (valore atteso): = y p(y) Varianza: 2= (y- )2p(y) y. 1.")
24
Distribuzioni di probabilità continue
y y x x a b Sono descritte da funzioni. Di queste ci interessa solo l’integrale L’area sottesa dalla curva è = 1 L’area sottesa dalla curva tra due valori (es. a-b) è la probabilità che la variabile casuale assuma valori compresi tra a e b 1
 è la probabilità che la variabile casuale assuma valori compresi tra a e b. 1.")
25
Distribuzioni di probabilità di interesse
Distribuzione binomiale Distribuzione normale Distribuzione del t di Student Distribuzione di F di Fisher Distribuzione del 2 Distribuzione di Poisson Distribuzione del Q Distribuzione binomiale negativa Distrib Gamma, beta, Cauchy, Gumbel, Weibull, Log-normale ecc…

26
Popolazione binomiale
Il caso più semplice di popolazione con variabili qualitative è la popolazione binomiale. Viene detta binomiale perché sono contemplate solo due possibilità, due possibili realizzazioni. Vengono quindi analizzate le proporzioni delle due realizzazioni contemplate, dove: p è la proporzione di individui che presentano una certa caratteristica (1-p) è la proporzione di individui che non la presentano.
 è la proporzione di individui che non la presentano.")
27
Distribuzione binomiale
Convenzionalmente ad una delle due realizzazioni possibili viene assegnata l’etichetta di “successo” e viene indicata con 1. L’altra (“insuccesso”) viene indicata con 0. Si indicano: P(1) = p P(0) = q = (1 - p) La distribuzione binomiale descrive la distribuzione di una variabile casuale Y che è il numero di successi in un campione di numerosità n, composto cioè da n realizzazioni indipendenti dell’evento elementare.
 viene indicata con 0. Si indicano: P(1) = p. P(0) = q = (1 - p) La distribuzione binomiale descrive la distribuzione di una variabile casuale Y che è il numero di successi in un campione di numerosità n, composto cioè da n realizzazioni indipendenti dell’evento elementare.")
28
Distribuzione binomiale
La variabile casuale Y (numero di successi in un campione di numerosità n) è una variabile discreta che ha possibili realizzazioni: 0, 1, 2, …, n Si tratta in sostanza di associare una probabilità a ciascuna di queste realizzazioni. La formula è la seguente: Dove y è una delle possibili realizzazioni di Y
 è una variabile discreta che ha possibili realizzazioni: 0, 1, 2, …, n. Si tratta in sostanza di associare una probabilità a ciascuna di queste realizzazioni. La formula è la seguente: Dove y è una delle possibili realizzazioni di Y.")
29
Origine distribuzione binomiale
Ho un sacco con 40 palline bianche e 60 nere. L’evento “successo” è dato dalla estrazione di una pallina bianca. Estraggo, con reimmissione, 5 palline. Quale probabilità di estrarre 2 palline bianche? p=0.4 q=0.6 n=5 y=2 - Se i successi sono 2, gli insuccessi saranno 5-2=3 - Poiché le realizzazioni sono indipendenti: P = 0.4*0.4*0.6*0.6*0.6 = = cioè: p2q3 = p2(1-p)3 = py(1-p)(n-y) Questa è la probabilità di una sola possibile sequenza di estrazioni con 2 successi. (prime 2 estrazioni successo, ultime 3 insuccesso)
3 = py(1-p)(n-y) Questa è la probabilità di una sola possibile sequenza di estrazioni con 2 successi. (prime 2 estrazioni successo, ultime 3 insuccesso)")
30
Origine distribuzione binomiale
Non avendo definito la sequenza di successi ed insuccessi a priori, per avere la probabilità di ottenere 2 successi in 5 realizzazioni devo considerare tutte le possibili combinazioni delle possibili estrazioni con 2 successi e applicare la regola additiva delle probabilità. Il numero delle combinazioni possibili si può ottenere dal calcolo combinatorio: Quindi la probabilità di estrarre due palline bianche estraendone 5 da una popolazione con p=0,4 è: p(2) = 10 x =
 = 10 x =")
31
Campione di numerosità 3 da popolazione con p=0.5

32
Campione di numerosità 3 da popolazione con p=0.1
q= 1- 0.9 d1 d2 d3 n succ P Probab. q*q*q 0.729 1 p*q*q 0.081 q*p*q 0.243 q*q*p 2 p*p*q 0.009 p*q*p 0.027 q*p*p 3 p*p*p 0.001 } 0.2 0.3 0.4 0.5 0.6 0.7 0.8 4 0 successi 1 successo 2 successi 3 successi

33
Caratteristiche della distribuzione binomiale
Dove y è una delle possibili realizzazioni di Y È descritta da un solo parametro: p Se i dati sono espressi come frequenze: Valore medio (valore atteso): =np Varianza: 2= np(1-p)
: =np. Varianza: 2= np(1-p)")
34
Distribuzione normale
Tra le varie distribuzioni di probabilità, una ha ruolo fondamentale in statistica: la distribuzione normale o Gaussiana Tra le proprietà della Gaussiana ricordiamo: La variabile x (variabile casuale) può avere valore da - a + E’ completamente definita da 2 parametri (media e varianza – ovvero dev. St.) e viene sinteticamente indicata con N(; ) E’ simmetrica intorno alla media ed è a forma di campana Ha il massimo in x= e 2 flessi in
 può avere valore da - a + E’ completamente definita da 2 parametri (media e varianza – ovvero dev. St.) e viene sinteticamente indicata con N(; ) E’ simmetrica intorno alla media ed è a forma di campana. Ha il massimo in x= e 2 flessi in ")
35
Distribuzione normale
Esistono infinite curve normali (per ogni possibile media & dev. st.) Le probabilità (superfici sottese) sono in relazione alle distanze dalla media misurata in numero di deviazioni standard
 Le probabilità (superfici sottese) sono in relazione alle distanze dalla media misurata in numero di deviazioni standard.")
36
la normale standardizzata
Tra le curve normali, si fa spesso riferimento alla cosiddetta “Normale standardizzata” che è N(0;1) e quindi ha: media = 0 deviazione standard = 1 Tutte le normali possono essere ricondotte alla normale standardizzata, sottraendo a ogni dato la media e dividendo per la deviazione standard. La distribuzione normale standardizzata si chiama distribuzione di Z
 e quindi ha: media = 0. deviazione standard = 1. Tutte le normali possono essere ricondotte alla normale standardizzata, sottraendo a ogni dato la media e dividendo per la deviazione standard. La distribuzione normale standardizzata si chiama distribuzione di Z.")
37
la normale standardizzata
Data una normale qualsiasi e un punto x, l’area compresa tra il punto x e + è la stessa di quella compresa tra il corrispondente z e + L’integrale della normale N(, ) tra x e + è calcolabile, ma con notevole difficoltà; l’integrale di z è invece tabulato. (l’integrale della normale N(, ) tra x e + ci dà la probabilità che un’unità sperimentale abbia un valore superiore a x)
 tra x e + è calcolabile, ma con notevole difficoltà; l’integrale di z è invece tabulato. (l’integrale della normale N(, ) tra x e + ci dà la probabilità che un’unità sperimentale abbia un valore superiore a x)")
38
Distribuzione binomiale -> normale
all’aumentare della numerosità campionaria la distribuzione binomiale tende alla normale. L’approssimazione è accettabile quando np5 e n(1-p)5
5.")
39
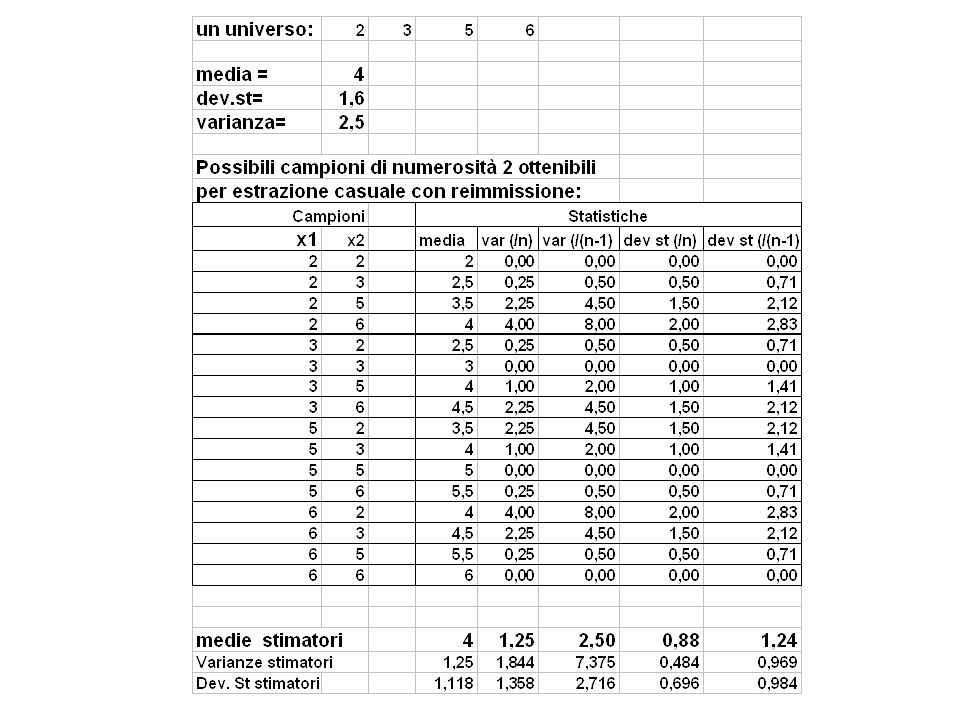
Stimatori Uno stimatore è una statistica ottenuta da un campione che stima un parametro della popolazione. Gli stimatori si indicano con lettera latina I parametri della popolazione si indicano con lettera greca Media stimatore di Varianza stimatore di Dev. St. stimatore di Lo strumento per valutare l’attendibilità di uno stimatore si basa sullo studio della probabilità

40
Stimatori e distribuzioni campionarie
Proprietà di uno stimatore Non distorsione (accuratezza): la media di tutti i possibili valori dello stimatore è uguale al valore del parametro della popolazione. Consistenza: all’aumentare della dimensione del campione lo stimatore tende al valore del parametro Efficienza (precisione): è più efficiente, tra tutti gli stimatori non distorti, quello che ha minore varianza campionaria
: la media di tutti i possibili valori dello stimatore è uguale al valore del parametro della popolazione. Consistenza: all’aumentare della dimensione del campione lo stimatore tende al valore del parametro. Efficienza (precisione): è più efficiente, tra tutti gli stimatori non distorti, quello che ha minore varianza campionaria.")
41
Stimatori di media e varianza
Il miglior stimatore della media di una popolazione è la media del campione. Il miglior stimatore della varianza di una popolazione è: Se si divide per n invece che per n-1 lo stimatore è distorto Non vi sono stimatori non distorti della deviazione standard, è per questo che si usa molto la varianza.

43
Teorema del limite centrale
Una variabile che derivi dalla somma di altre tende a essere distribuita normalmente. Tante più variabili concorrono alla somma tanto più l’approssimazione è buona Le medie campionarie, anche se i campioni sono tratti da popolazioni con distribuzioni diverse dalla normale, tendono ad essere distribuite normalmente. L’approssimazione è tanto maggiore quanto maggiore è la numerosità campionaria

44
Distribuzione campionaria delle medie
la distribuzione campionaria della media di un campione di numerosità n estratto casualmente da una popolazione di media e varianza 2 ha: media = (stimatore non distorto) varianza = deviazione standard = Inoltre, per il teorema del limite centrale, se n (numerosità del campione) è sufficiente, la distribuzione delle medie campionarie è normale
 varianza = deviazione standard = Inoltre, per il teorema del limite centrale, se n (numerosità del campione) è sufficiente, la distribuzione delle medie campionarie è normale.")
45
Errore standard della media
La deviazione standard della distribuzione delle medie campionarie, più piccola di di un fattore , si chiama errore standard o deviazione standard della media o errore di campionamento della media. Errore standard: Errore percentuale:

46
Distribuzione campionaria di una proporzione
La distribuzione binomiale (popolazione) descrive la probabilità di Y (numero di successi) in un campione di numerosità n. Se ci si riferisce alle proporzioni di successi, è caratterizzata da: Media (valore atteso): =p Varianza: 2= p(1-p) L’estrazione di un campione casuale di numerosità n fornirà una proporzione campionaria di successi. La proporzione di successi del campione, se n è sufficiente, è una variabile casuale con distribuzione approssimativamente normale e: Media = p Varianza = p(1-p)/n
 descrive la probabilità di Y (numero di successi) in un campione di numerosità n. Se ci si riferisce alle proporzioni di successi, è caratterizzata da: Media (valore atteso): =p. Varianza: 2= p(1-p) L’estrazione di un campione casuale di numerosità n fornirà una proporzione campionaria di successi. La proporzione di successi del campione, se n è sufficiente, è una variabile casuale con distribuzione approssimativamente normale e: Media = p. Varianza = p(1-p)/n.")
47
La distribuzione del t di Student
Ve ne sono infinite, in funzione della dimensione campionaria. In altri termini l’unico parametro della distribuzione sono i GL di s. Per n= la distribuzione del t diviene quella di z. Nella distribuzione delle medie campionarie: con:

48
La distribuzione del t di Student
E’ simmetrica, più appiattita della normale (è tanto più platicurtica tanto più piccola è la dimensione campionaria). E’ tabulata per il n° di gradi di libertà (n-1) con cui si stima la deviazione standard
. E’ tabulata per il n° di gradi di libertà (n-1) con cui si stima la deviazione standard.")
49
La distribuzione F Serve a descrivere la distribuzione del rapporto di due stime della varianza. Dati due campioni indipendenti, estratti da popolazioni con distribuzione normale e varianze 21 22 È una variabile casuale con la distribuzione F La distribuzione F ha due parametri: 1 e 2 che sono i gradi di libertà con cui sono calcolate le varianze stimate s2. Si indica con F(1, 2)
")
50
Definita solo per valori non negativi Asimmetrica
La distribuzione F Definita solo per valori non negativi Asimmetrica Per ogni combinazione di gradi di libertà esiste una distribuzione Bisogna scegliere quale varianza mettere a numeratore. Per convenzione si mette sempre la varianza più grande. Se 21= 22

51
Distribuzione del X2 E’ data dalla sommatoria di n variabili indipendenti z2. E’ sempre positiva. E’ composta da n quote additive a ciascuna delle quali compete 1 grado di libertà (GL). I GL sono quindi dati dal numero di variabili z2 sommate. Per 1 GL, X2=z2
. I GL sono quindi dati dal numero di variabili z2 sommate. Per 1 GL, X2=z2.")
52
Distribuzione del X2 Può essere usata per descrivere la distribuzione della varianza campionaria. Infatti: Ovvero: Ha la distribuzione di X2 con (n-1) GL.
 GL.")
Presentazioni simili
 e nel verificare se con i dati a disposizione è possibile rifiutarla o no.>")
 GLI INTERVALLI DI CONFIDENZA>")

















