Scaricare la presentazione
La presentazione è in caricamento. Aspetta per favore

1
Elaborazione statistica di dati

2
CONCETTI DI BASE DI STATISTICA ELEMENTARE

3
Taratura strumenti di misura
IPOTESI: grandezza da misurare identica da misura a misura Per la presenza di errori casuali, ripetendo più volte la misura di una stessa grandezza, si può ottenere una serie di valori diversi.

4
Collaudo sistemi di produzione
IPOTESI: accuratezza strumento di misura migliore della variabilità dei manufatti Una serie di valori di misure casualmente diverse può essere ottenuta anche misurando diversi elementi, nominalmente uguali, di una produzione industriale.

5
Esempio di serie di dati:
Lo spessore di 110 dadi estratti dalla produzione di una macchina

6
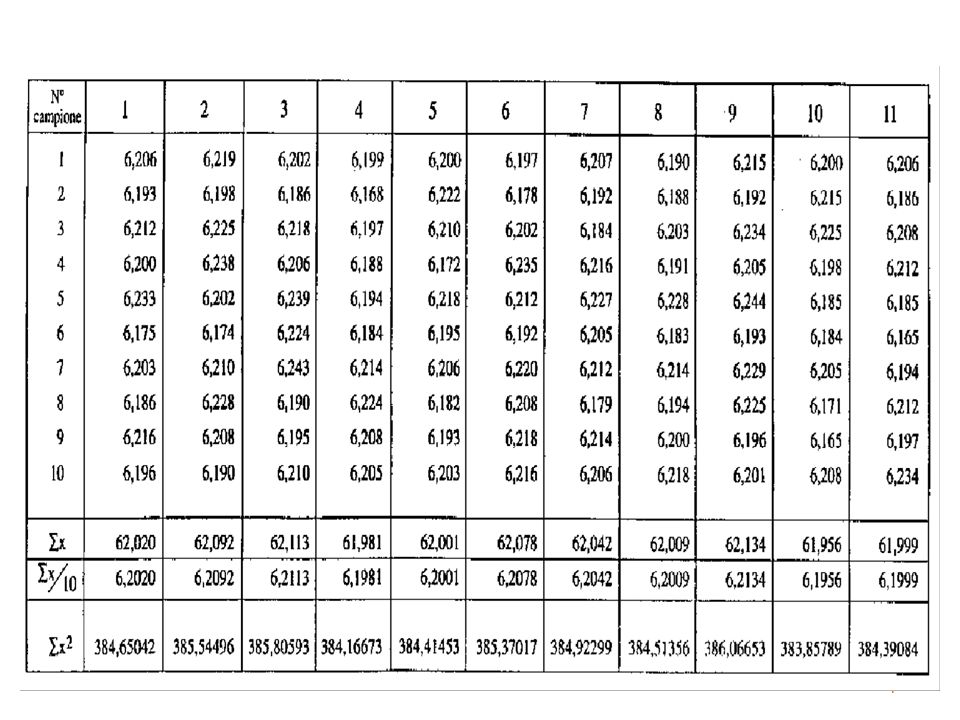
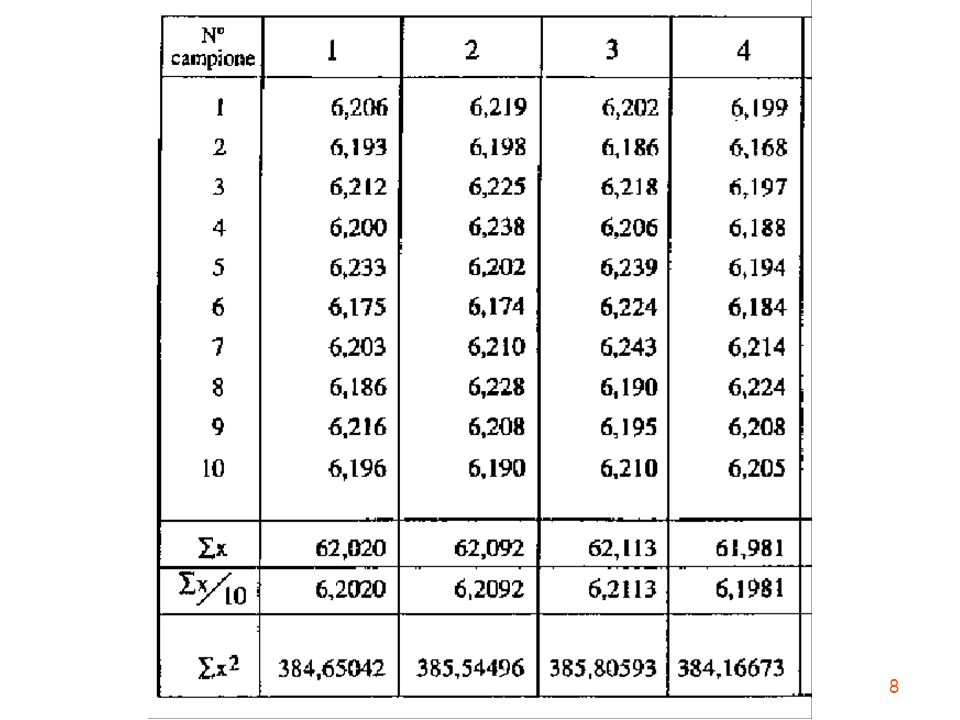
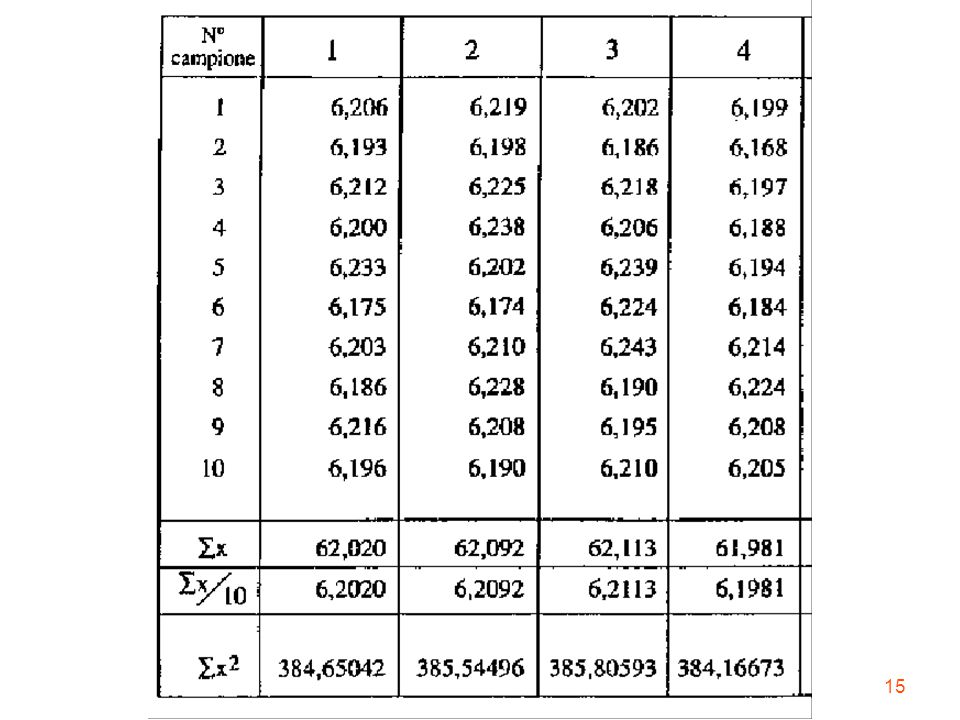
Ogni serie di valori estratta dalla totalità dei valori possibili può essere considerato un campione. Esistono vari metodi per estrarre un campione che sia rappresentativo dell'universo. Qui si considerano 11 campioni estratti casualmente. Ciascun campione contiene 10 misure di spessore

9
Al sottoinsieme di “n” valori estratti dall’insieme dei valori possibili viene dato il nome di campione; l’intero insieme di dati “N” viene definito popolazione (o universo).
.")
10
CAMPIONE 1 n x i media m= x 1 n-1 i (x n -x)2 varianza s2
2 varianza s2")
11
La media gode della proprietà di rendere minima la somma dei quadrati degli scarti. Inoltre la somma algebrica degli scarti rispetto al valore medio è nulla.

12
La radice quadrata della varianza s, costituisce una stima della dispersione delle misure intorno al valore medio, al pari di s2, ma ha il pregio di avere le stesse dimensioni delle misure x.

13
I due parametri precedenti nel caso della popolazione, o universo composto di N elementi, si indicano con i simboli: 1 N x i 2 ( 2 )
")
14
I dati possono essere raggruppati in diversi modi
I dati possono essere raggruppati in diversi modi. Una prima forma di raggruppamento si può osservare nella tabella.

16
Una forma di raggruppamento molto più usata e significativa è quella delle classi di intervalli di appartenenza, che non è necessario abbiano tutti la stessa ampiezza.

17
Raggruppando per intervalli:
Frequenza Valore Frequenza Frequenza Densità di Limiti delle cumulata centrale assoluta percentuale frequenza classi percentuale della classe f fp j f j k > di < di x ( mm ) f f = 100 100 (%) j j p n x n m m m m k=1 (%) 6,160 6,170 6,165 3 2,73 0,273 2,73 6,170 6,180 6,175 6 5,45 0,545 8,18 6,180 6,190 6,185 12 10,91 1,091 19,09 6,190 6,200 6,195 23 20,91 2,091 40,00 6,200 6,210 6,205 26 23,64 2,364 63,64 6,210 6,220 6,215 21 19,09 1,909 82,73 6,220 6,230 6,225 11 10,00 1,000 92,73 6,230 6,240 6,235 6 5,45 0,545 98,18 6,240 6,250 6,245 2 1,82 0,182 100,00
 f. f. = (%) j. j. p. n. x. n. m. m. m. m. k=1. (%) 6,160. 6,170. 6, ,73. 0,273. 2,73. 6,170. 6,180. 6, ,45. 0,545. 8,18. 6,180. 6,190. 6, ,91. 1, ,09. 6,190. 6,200. 6, ,91. 2, ,00. 6,200. 6,210. 6, ,64. 2, ,64. 6,210. 6,220. 6, ,09. 1, ,73. 6,220. 6,230. 6, ,00. 1, ,73. 6,230. 6,240. 6, ,45. 0, ,18. 6,240. 6,250. 6, ,82. 0, ,00.")
18
Il numero dei dati che appartengono a una determinata classe j si chiama frequenza della classe e viene indicato con fj.

19
Il raggruppamento in k classi o sottogruppi, G1. Gj
Il raggruppamento in k classi o sottogruppi, G1...Gj...Gk, avviene secondo il valore, ad esempio se a è il minimo degli xi e b il massimo: x G i j a + - < ( ) 1 b k = se
 1. b. k. = se.")
20
fp,i è compreso nell'intervallo [0-100]%
Ad ogni classe Gi è associato il numero di elementi che vi appartengono, fi . Si definisce frequenza relativa percentuale della classe il parametro: compreso nell'intervallo [0,1], che chiameremo frequenza dell'evento E, relativa alle N prove o frequenza relativa. f è la frequenza con cui accade l’enento nelle N prove f n p i , 100 fp,i è compreso nell'intervallo [0-100]%
![fp,i è compreso nell intervallo [0-100]%](http://slideplayer.it/slide/5505555/17/images/20/fp%2Ci+%C3%A8+compreso+nell+intervallo+%5B0-100%5D%25.jpg "Ad ogni classe Gi è associato il numero di elementi che vi appartengono, fi . Si definisce frequenza relativa percentuale della classe il parametro: compreso nell intervallo [0,1], che chiameremo frequenza dell evento E, relativa alle N prove o frequenza relativa. f è la frequenza con cui accade l’enento nelle N prove. f. n. p. i. , 100. fp,i è compreso nell intervallo [0-100]%")
21
Raggruppando per intervalli:
Frequenza Valore Frequenza Frequenza Densità di Limiti delle cumulata centrale assoluta percentuale frequenza classi percentuale della classe f fp j f j k > di < di x ( mm ) f f = 100 100 (%) j j p n x n m m m m k=1 (%) 6,160 6,170 6,165 3 2,73 0,273 2,73 6,170 6,180 6,175 6 5,45 0,545 8,18 6,180 6,190 6,185 12 10,91 1,091 19,09 6,190 6,200 6,195 23 20,91 2,091 40,00 6,200 6,210 6,205 26 23,64 2,364 63,64 6,210 6,220 6,215 21 19,09 1,909 82,73 6,220 6,230 6,225 11 10,00 1,000 92,73 6,230 6,240 6,235 6 5,45 0,545 98,18 6,240 6,250 6,245 2 1,82 0,182 100,00
 f. f. = (%) j. j. p. n. x. n. m. m. m. m. k=1. (%) 6,160. 6,170. 6, ,73. 0,273. 2,73. 6,170. 6,180. 6, ,45. 0,545. 8,18. 6,180. 6,190. 6, ,91. 1, ,09. 6,190. 6,200. 6, ,91. 2, ,00. 6,200. 6,210. 6, ,64. 2, ,64. 6,210. 6,220. 6, ,09. 1, ,73. 6,220. 6,230. 6, ,00. 1, ,73. 6,230. 6,240. 6, ,45. 0, ,18. 6,240. 6,250. 6, ,82. 0, ,00.")
22
Rappresentazione della
DENSITA’ DI PROBABILITA’

23
Nell’esempio precedente per ognuna delle classi Gi è possibile definire la probabilità pi che una misura qualsiasi ricada nell’intervallo della classe i-esima vale: In taluni casi particolari, ma estremamente importanti, è addirittura possibile ridurre tale informazione alla conoscenza di alcuni parametri significativi. ad esempio per la distribuzione gaussiana è sufficiente conoscere la media e la varianza. p f n i lim NOTA: il limite può andare ad infinito oppure N nel caso di popolazioni con numero limitato di possibili elementi

24
La densità di probabilità viene espressa con l’andamento delle probabilità pi in funzione delle k classi. La rappresentazione della densità di probabilità può essere fatta o con l’istogramma delle frequenze o con il poligono delle frequenze, cioè mediante k punti discreti. In taluni casi particolari, ma estremamente importanti, è addirittura possibile ridurre tale informazione alla conoscenza di alcuni parametri significativi. ad esempio per la distribuzione gaussiana è sufficiente conoscere la media e la varianza.

25
Per variabili discrete valgono le seguenti relazioni:
x i K s t k 1 2 ; ( ) , ps,t rappresenta la probabilità cumulata delle classi da s a t ovvero del verificarsi che : x s t
 , ps,t rappresenta la probabilità cumulata delle classi da s a t ovvero del verificarsi che : x. s. t. ")
26
10% = Percentuale di dati con valore compreso in questa classe
24 22 20 18 16 Frequenza_relativa [%] 14 12 10 8 6 4 2 6.165 6.245 valore centrale della classe

27
Poligono delle frequenze
24 22 20 18 16 14 Frequenza relativa [%] 12 10 8 6 4 2 6.16 6.17 6.18 6.19 6.20 6.21 6.22 6.23 6.24 6.25 x [mm]

28
Un diagramma di tipo diverso si ottiene rappresentando le frequenze cumulate. In corrispondenza al limite superiore di ogni classe si riporta la frequenza relativa percentuale dei dati che hanno una misura inferiore a quel limite.

29
limite superiore della classe mm
6.17 6.18 6.19 6.20 6.21 6.22 6.23 6.24 6.25 10 20 30 40 50 60 70 80 90 100 Frequenze cumulate percentuali k = 4 % dati che assumono valori minori di xk limite superiore della classe mm

30
distribuzione di Gauss Frequenza relativa
6.16 6.17 6.18 6.19 6.20 6.21 6.22 6.23 6.24 6.25 x (mm) 2 4 6 8 10 12 14 16 18 20 22 24 distribuzione di Gauss Frequenza relativa frequenza relativa
 distribuzione di Gauss. Frequenza relativa. frequenza relativa.")
31
LE DISTRIBUZIONI DI PROBABILITA’
In taluni casi particolari, ma estremamente importanti, è addirittura possibile ridurre tale informazione alla conoscenza di alcuni parametri significativi. ad esempio per la distribuzione gaussiana è sufficiente conoscere la media e la varianza.

32
Variabili continue

33
Nell’esempio precedente se si considera lo spessore del dado che quindi è una variabile continua.
Ogni valore dell’altezza è possibile e la distribuzione di probabilità è rappresentata da una funzione continua.

34
LA DISTRIBUZIOINE GAUSSIANA NORMALE E TEOREMA DEL LIMITE CENTRALE

35
PDF (Probability Density Function) gaussiana (o normale)
f(x) 1 2 e x f (x) mx=valore medio x=varianza Quanto più è ampio sigma tanto più è distribuita e bassa la PDF
 e. x. f (x) mx=valore medio x=varianza. Quanto più è ampio sigma tanto più è distribuita e bassa la PDF.")
36
Perché il modello gaussiano di probabilità è sovente impiegato nell’ingegneria?

37
Il teorema del limite centrale afferma che la distribuzione delle medie tende ad essere normale anche se la distribuzione di origine non lo è.

38
Inoltre, come è evidente dall’animazione la distribuzione della media gode delle seguenti due proprietà: Ha la stessa media (la distribuzione non si ‘sposta’) Ha una deviazione standard minore (la distribuzione si ‘stringe’) pari a: / √n
 Ha una deviazione standard minore (la distribuzione si ‘stringe’) pari a: / √n.")
39
Esempio: distribuzione della variabile somma
probabilità di aB = aA = bB = bA = 50% probabilità di aB + bB = 25% probabilità valore basso = 25% probabilità di aB + bA = 25% probabilità valore medio = 50% probabilità di aA + bB = 25% probabilità di aA + bA = 25% probabilità valore alto = 25% Distribuzione di ‘a’ Distribuzione di ‘a+b’ aB aA Distribuzione di ‘b’ bB bA

40
mx=valore medio x=varianza
Il teorema limite centrale afferma che la distribuzione gaussiana permette di descrivere in maniera soddisfacente tutti quei fenomeni fisici caratterizzati dalla sovrapposizione di un elevato numero di effetti deboli indipendenti aventi loro natura statistica a media nulla. mx=valore medio x=varianza

41
Conseguenza di tale teorema è che nel caso in cui si abbia un fenomeno dato dalla sovrapposizione di numerosi effetti, nonostante singolarmente siano dotati di distribuzione non gaussiana, il fenomeno complessivo sarà normalmente distribuito, purché essi siano indipendenti e nessuno degli effetti sia prevalente Dal momento che i fenomeni del mondo reale sono spesso il risultato del contributo di molti eventi casuali non osservabili, questo teorema fornisce una spiegazione per la prevalenza ‘in natura’ della distribuzione di probabilità normale.

42
Data una distribuzione qualsiasi di risultati di un processo di misurazione che abbia media e scarto quadratico Anche ipotizzando PDF non gaussiana, se si estraggono non singole misure ma campioni sufficientemente numerosi, n > , la distribuzione delle medie delle misure segue quasi fedelmente la legge di distribuzione normale (di Gauss) … QUINDI SI CONOSCE LA VARIABILITA’ ED E’ POSSIBILE QUANTIFICARE GLI INTERVALLI DI CONFIDENZA !!!
 … QUINDI SI CONOSCE LA VARIABILITA’ ED E’ POSSIBILE QUANTIFICARE GLI INTERVALLI DI CONFIDENZA !!!")
43
Inoltre la media di tali medie è ancora m e lo scarto quadratico si riduce a:
E QUINDI MIGLIORA L’ACCURATEZZA !!! … per questo motivo è sempre opportuno ripetere più volte una misura e prendere come migliore stima il valore medio !!!

44
DISTRIBUZIONE CUMULATA E DISTRIBUZIONE NORMALE STANDARD

45
z = x - f(z) 1 2 e Distribuzione normale standard
f (z) Il valor medio è nullo e la varianza è pari ad 1 5
 Il valor medio è nullo e la varianza è pari ad")
46
F(z) = p(zi z) Frequenze cumulate Grafico delle Frequenze cumulate
-3 -2 -1 1 2 3 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 F (z) Analisi della normalità della distribuzione Il grafico di probabilità normale (GPN) 1 Grafico delle Frequenze cumulate Il valor medio è in corrispondenza del 50% di probabilità cumulata
 Analisi della normalità della distribuzione Il grafico di probabilità normale (GPN) 1. Grafico delle. Frequenze cumulate. Il valor medio è in corrispondenza del 50% di probabilità cumulata.")
47
F(z) = p(zi z) z1 z2 Utilità della funzione cumulata: F(z2) F(z1)
0.9 0.8 F(z) = p(zi z) 0.7 0.6 0.5 0.4 0.3 F(z1) Analisi della normalità della distribuzione Il grafico di probabilità normale (GPN) 1 0.2 0.1 -3 -2 -1 1 2 3 z1 z2 p(zi [z1,z2]) = p(zi < z2) - p(zi < z1) p(zi [z1,z2]) = F(z2) - F(z1)
 = p(zi z) F(z1) Analisi della normalità della distribuzione Il grafico di probabilità normale (GPN) z1. z2. p(zi [z1,z2]) = p(zi < z2) - p(zi < z1) p(zi [z1,z2]) = F(z2) - F(z1)")
48
Nota sulla relazione di prima:
Si può dire in due modi diversi lo stesso concetto: la probabilità che il valore appartenga all’intervallo è pari alla probabilità che sia inferiore all’estremo superiore e superiore all’estremo inferiore la probabilità che il valore appartenga all’intervallo è pari alla probabilità che sia inferiore all’estremo superiore ma non inferiore all’estremo inferiore Analisi della normalità della distribuzione Il grafico di probabilità normale (GPN) 1 p(zi [z1,z2]) = p(zi < z2) - p(zi < z1)
 1. p(zi [z1,z2]) = p(zi < z2) - p(zi < z1)")
49
-3 -2 -1 1 2 3 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 z p(zi<z) = F(z) p(zi >z) p(zi [z1,z2]) = F(z2) - F(z1) Usando la variabile non normalizzata p(xi [, ]) = F() - F() = F(z=1) - F(z=-1) Valori notevoli spiegare il significato di questi valori 5 p x ( ) . 680 2 950 3 997 z
 = F(z2) - F(z1) Usando la variabile non normalizzata. p(xi [, ]) = F() - F() = F(z=1) - F(z=-1) Valori notevoli. spiegare il significato di questi valori. 5. p. x. ( ) . z.")
50
Oppure, ad esempio: p(zi >z) p(zi<z) = F(z) z
-3 -2 -1 1 2 3 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 z p(zi<z) = F(z) p(zi >z) Oppure, ad esempio: Valori notevoli spiegare il significato di questi valori 5 La distribuzione normale è simmetrica: z
 = F(z) p(zi >z) Oppure, ad esempio: Valori notevoli. spiegare il significato di questi valori. 5. La distribuzione normale è simmetrica: z.")
51
Esempio: - supponiamo di voler misurare la temperatura - al fine di associare l’intervallo di confidenza alla misura ottenuta si opera come segue: 1: si effettuano un numero N, limitato, di ripetizioni (circa 20 ad esempio) 2: si calcola da tale campione statistico media Tm e deviazione standard Sm 3: il risultato sarà pari a Tm ± 2Sm/√N (95% lc) NOTA: tale risultato vale anche se il fenomeno aleatorio associato alla misura non è gaussiano
 2: si calcola da tale campione statistico media Tm e deviazione standard Sm. 3: il risultato sarà pari a Tm ± 2Sm/√N (95% lc) NOTA: tale risultato vale anche se il fenomeno aleatorio associato alla misura non è gaussiano.")
Presentazioni simili
 GLI INTERVALLI DI CONFIDENZA>")











>")






